
繼去年NVIDIA 首席執行長黃仁勳在台大畢典的演講在台掀起一波熱潮後,黃仁勳在日前又到台大體育館舉行Computex演講啦!這次演講主題圍繞著 AI,黃仁勳分享了未來的科技願景、以及行業的突破性進展,本文將提供2小時全演講的中英逐字稿,以及7點重點整理,幫著讀者快速掌握這次的演講內容。
一、感謝與台灣的合作
黃仁勳感謝台灣供應鏈夥伴的支持,強調台灣是 NVIDIA 的重要合作夥伴,並展示了 NVIDIA 與台積電、華碩、鴻海等台灣企業的合作成果。他表示,台灣與 NVIDIA 的合作創造了 AI 的基礎架構,為全球科技進展提供了重要支持。黃仁勳特別提到,他與台積電創辦人張忠謀一同逛夜市,並分享了他對台灣夜市的深厚感情,贏得觀眾如雷掌聲。

二、生成式 AI:行業的全新轉變
黃仁勳強調,AI 將引領新一波產業革命,IT 產業不再只是製造電腦,而是變成為各產業生成智慧的工廠。生成式 AI 不僅能創建文本和圖像,還能生成模擬,對醫療、金融和製造等領域產生深遠影響。
黃仁勳也強調了新技術在處理數據和計算的需求上呈現指數增長,也因此比起現有的 CPU的進步速度,更高效、高成長的GPU變得更重要,可以顯著降低成本和能源消耗,使計算更加高效和持續。

三、NIM:數字人類能夠更自然地與人互動
黃仁勳介紹了今年 3 月推出的 NVIDIA NIM(AI 模型推理服務),這是一套加速企業導入 AI 模型的工具。開發者可以快速部署人工智慧模型,大幅減少開發時間和導入門檻,涵蓋藥物開發中的化學分子合成、數位人類的互動影像生成、客服機器人、遊戲、廣告等應用。
這些數字人類技術基於多語言語音識別和合成、理解和生成對話的大型語言模型(LLM),和視覺語言模型(VLM),並結合了動態3D面部網格動畫和實時路徑追蹤次表面散射技術,使得數字人類能夠以更加自然和真實的方式與人類互動。

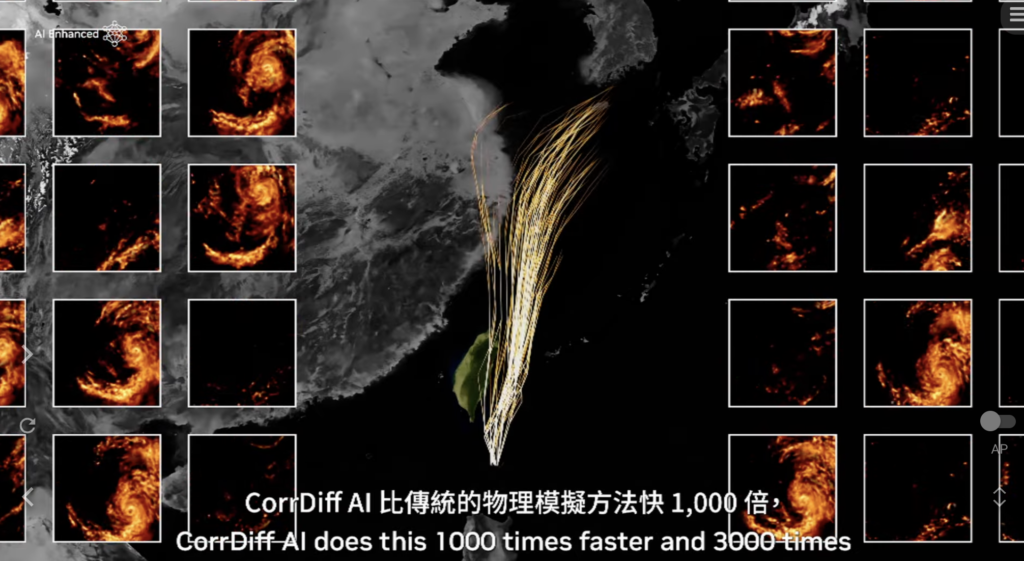
四、數位孿生:即時氣象預測
黃仁勳展示了 NVIDIA 開發的氣候數位孿生雲端平台 Earth-2,利用生成式 AI、物理學和觀測技術,來模擬氣候變遷對地球的影響。傳統方法需耗時數小時生成的氣象圖,透過 Earth-2 僅需幾秒鐘,幫助氣象單位即時更新預報結果。目前交通部中央氣象署也利用這套模型預測颱風登陸的位置。
五、AI 工廠:新工業革命
他提出了AI工廠的概念,這是一個生產生成式AI模型的工廠,能夠為每個行業生成具有巨大價值的新商品。他預測,未來AI將能夠學習物理定律,NVIDIA Omniverse 在其中提供了一個開發和測試這些系統的虛擬環境,然後再部署到現實世界中。
同時,數據生成速度將繼續增長,推動AI模型的持續增長和更大規模的計算需求。
生成式 AI 將從虛擬世界走向實體世界,應用於各種機器人,這些機器人能夠理解人們的指令,自主執行複雜的任務。生成式 AI 強化了機器人的動作學習,提高其動作的精準度,未來能應用於實體工廠,促進無人工廠的實現。

七、Blackwell:AI 計算的新飛躍
Blackwell GPU,這款被譽為「地表最強 AI 晶片」的產品,能讓 AI 運算力在 8 年內增加 1000 倍,成本和能耗比前一代(Hopper 晶片)低至少 25 倍。具體來說,訓練 ChatGPT-4 模型所需的運算電力只要原本的 1/350。Blackwell 預計在 2024 年下半年出貨,黃仁勳表示,明年會推出 Blackwell Ultra,並透露下一代名為「Rubin」GPU 架構已在開發中,預計 2026 年推出。
未來的GPU,可以使得訓練大型語言模型所需的能量大幅減少。

2024 黃仁勳台大演講 中英全文逐字稿
影片網址:https://www.youtube.com/watch?v=5wBfTqWe34A
20:04
「我非常高興能回來,感謝N讓我們使用你的體育場。上次我在這裡,我從N那裡獲得了一個學位,我給了‘不要走,跑’的演講。今天我們有很多事情要談,所以我不能走,我必須跑。我有很多事情要告訴你們,我很高興能在台灣。台灣是我們珍貴夥伴的家。」
“I am very happy to be back. Thank you, N, for letting us use your stadium. The last time I was here, I received a degree from N, and I gave the ‘Run, don’t walk’ speech. And today we have a lot to cover, so I cannot walk, I must run. We have a lot to cover. I have many things to tell you. I’m very happy to be here in Taiwan. Taiwan is the home of our treasured partners.”
21:03
「事實上,我們所做的一切都是從這裡開始的,我們的合作夥伴和我們一起將它帶到世界。」
“This is, in fact, where everything NVIDIA does begins. Our partners and ourselves take it to the world.”
21:26
「台灣和我們的合作創造了今天的全球AI基礎設施。今天我想談幾件事情。」
“Taiwan and our partnership has created the world’s AI infrastructure. Today, I want to talk to you about several things.”
22:28
「一是發生了什麼以及我們一起做的工作的意義,什麼是生成AI,它對我們行業和每個行業的影響,我們將如何前進和抓住這個令人難以置信的機會,以及接下來會發生什麼。生成AI及其影響,我們的藍圖和接下來的事情,這些都是非常激動人心的時刻,我們的計算機行業的重新啟動,一個你們已經打造的行業,現在我們準備迎接下一個重大旅程。」
“One, what is happening and the meaning of the work that we do together, what is generative AI, what is its impact on our industry and on every industry, a blueprint for how we will go forward and engage this incredible opportunity, and what’s coming next. Generative AI and its impact, our blueprint, and what comes next. These are really, really exciting times, a restart of our computer industry, an industry that you have forged, an industry that you have created, and now we prepare for the next major journey.”
22:28
「但在我們開始之前,NVIDIA位於計算機圖形、模擬和人工智能的交匯處,這是我們的靈魂。我今天向你展示的一切都是模擬的,是數學,是科學,是計算機科學,是驚人的計算機架構,這些都不是動畫,都是自製的,這是NVIDIA的靈魂,我們把它全部放進了這個叫做Omniverse的虛擬世界。請欣賞。」
“But before we start, NVIDIA lives at the intersection of computer graphics, simulations, and artificial intelligence. This is our soul. Everything that I show you today is simulation, it’s math, it’s science, it’s computer science, it’s amazing computer architecture, none of it’s animated, and it’s all homemade. This is NVIDIA’s soul, and we put it all into this virtual world we called Omniverse. Please enjoy.”
25:52
「我想用中文對你們講,但我有太多的事情要告訴你們,我用中文說要想得太辛苦,所以我必須用英文對你們講。在你們看到的一切的基礎上,是兩項基本技術,加速計算和人工智能,這些技術運行在Omniverse內部,這兩項技術,這兩個基本的計算力量,將重新塑造計算機行業。」
“I want to speak to you in Chinese, but I have so much to tell you. I have to think too hard to speak Chinese, so I have to speak to you in English. At the foundation of everything that you saw were two fundamental technologies: accelerated computing and artificial intelligence running inside the Omniverse. Those two technologies, those two fundamental forces of computing, are going to reshape the computer industry.”
27:18
「計算機行業現在大約有60年了,很多我們今天所做的事情在我出生的1964年之後的一年就被發明了。IBM系統360引入了中央處理單元、通用計算、硬件和軟件的分離通過操作系統、多任務、IO子系統、DMA,所有我們今天使用的技術,架構兼容性、向後兼容性、家庭兼容性,所有我們今天知道的計算機技術大多在1964年描述出來的。」
“The computer industry is now some 60 years old. In a lot of ways, everything that we do today was invented the year after my birth in 1964. The IBM system 360 introduced central processing units, general-purpose computing, the separation of hardware and software through an operating system, multitasking, IO subsystems, DMA—all kinds of technologies that we use today. Architectural compatibility, backwards compatibility, family compatibility—all of the things that we know today about computing were largely described in 1964.”
27:18
「當然,PC革命使計算機普及,並把它放在了每個人的手中和家中,然後在2007年iPhone引入了移動計算,把計算機放在了我們的口袋裡。自那以來,一切都一直連接並運行在移動雲上。在這過去的60年裡,我們只見過幾次主要的技術變革,不多,只有兩三次,每一次都改變了一切,我們即將再次看到這種情況發生。」
“Of course, the PC revolution democratized computing and put it in the hands and the houses of everybody. And then, in 2007, the iPhone introduced mobile computing and put the computer in our pocket. Ever since, everything is connected and running all the time through the mobile cloud. In the last 60 years, we’ve seen only a few major technological shifts, not that many, just two or three. Each time, everything changed, and we’re about to see that happen again.”
28:04
「有兩件基本的事情正在發生。首先是處理器,計算機行業運行的引擎,中央處理單元的性能提升已經大大減慢,而我們必須做的計算量仍在快速增加,以指數級增長。如果處理需求,如果我們需要處理的數據繼續以指數級增長」
“There are two fundamental things that are happening. First, the processor, the engine by which the computer industry runs—the central processing unit—the performance scaling has slowed tremendously, and yet the amount of computation we have to do is still doubling very quickly, exponentially.”
28:37
「如果性能不增長,我們將會經歷計算膨脹,事實上,我們現在就在經歷這個情況。全世界的數據中心用電量正在大幅增加,計算成本正在上升。我們正在經歷計算膨脹。」
“Performance does not, we will experience computation inflation, and in fact, we’re seeing that right now as we speak. The amount of data center power that’s used all over the world is growing quite substantially. The cost of computing is growing. We are seeing computation inflation.”
28:58
「這當然不能持續下去,數據將繼續指數級增長,而CPU性能增長不會再回來。」
“This, of course, cannot continue. The data is going to continue to increase exponentially, and CPU performance scaling will never return.”
29:08
「有一種更好的方式,幾乎二十年來,我們一直在研究加速計算。CUDA增強了CPU,卸載並加速專用處理器可以做得更好的工作,事實上,性能如此卓越,現在很明顯,隨著CPU性能增長放緩並實質上停止,我們應該加速一切。」
“There is a better way. For almost two decades now, we’ve been working on accelerated computing. CUDA augments a CPU, offloads and accelerates the work that a specialized processor can do much, much better. In fact, the performance is so extraordinary that it is very clear now, as CPU scaling has slowed and effectively stopped, we should accelerate everything.”
29:37
「我預測每個需要大量處理的應用程序都將被加速,並且每個數據中心在不久的將來都將被加速。」
“I predict that every application that is processing-intensive will be accelerated, and surely every data center will be accelerated in the near future.”
29:48
「現在,加速計算非常合理,非常符合常識。如果你看一個應用程序,這裡的100t代表100個時間單位,可以是100秒,也可以是100小時,在許多情況下,如你所知,我們現在在人工智能應用程序上工作,有些運行100天。」
“Now, accelerated computing is very sensible, it’s very common sense. If you take a look at an application, and here the 100t means 100 units of time. It could be 100 seconds, it could be 100 hours. And in many cases, as you know, we’re now working on artificial intelligence applications that run for 100 days.”
30:05
「一個t是需要順序處理的代碼,單線程CPU在這裡非常重要,操作系統控制邏輯,真的很重要的是一個指令接著一個指令執行。」
“One t is code that requires sequential processing, where single-threaded CPUs are really quite essential. Operating systems control logic, really essential to have one instruction executed after another instruction.”
30:29
「然而,有許多算法,例如計算機圖形,你可以完全並行運行。計算機圖形、圖像處理、物理模擬、組合優化、圖處理、數據庫處理,當然還有非常著名的深度學習線性代數。」
“However, there are many algorithms, computer graphics is one, that you can operate completely in parallel. Computer graphics, image processing, physics simulations, combinatorial optimizations, graph processing, database processing, and of course, the very famous linear algebra of deep learning.”
30:51
「有很多類型的算法非常適合通過並行處理加速,所以我們發明了一種架構來實現這一點,通過將GPU添加到CPU,專用處理器可以將需要大量時間的任務加速到非常快的速度,因為兩個處理器可以並肩工作,它們都是自主的,都是獨立的。」
“There are many types of algorithms that are very conducive to acceleration through parallel processing. So we invented an architecture to do that by adding the GPU to the CPU. The specialized processor can take something that takes a great deal of time and accelerate it down to something that is incredibly fast. And because the two processors can work side by side, they’re both autonomous and they’re both separate and independent.”
31:21
「我們可以將原本需要100個時間單位的任務加速到只需要一個時間單位。速度的提升是難以置信的,幾乎聽起來像是不可思議的。」
“That is, we could accelerate what used to take 100 units of time down to one unit of time. Well, the speed up is incredible. It almost sounds unbelievable.”
31:40
「今天我會為你展示許多例子,這種益處是非常了不起的,100倍的速度提升,但你只增加了大約3倍的功率,並且成本只增加了大約50%。」
“It almost sounds unbelievable, but today I’ll demonstrate many examples for you. The benefit is quite extraordinary, a 100 times speed up, but you only increase the power by about a factor of three, and you increase the cost by only about 50%.”
31:57
「我們在PC行業中經常這樣做,我們在1000美元的PC中添加一個500美元的GeForce GPU,性能大幅提升。我們在數據中心中這樣做,一個十億美元的數據中心,我們添加價值5億美元的GPU,突然間,它變成了一個AI工廠。」
“We do this all the time in the PC industry. We add a GPU, a $500 GeForce GPU, to a $1,000 PC, and the performance increases tremendously. We do this in a data center, a billion-dollar data center, we add $500 million worth of GPUs, and all of a sudden, it becomes an AI factory.”
32:21
「這在全球各地都在發生,節省的成本是非常驚人的,你每美元獲得60倍的性能提升,100倍的速度提升,只增加3倍的功率,100倍的速度提升,成本只增加1.5倍。」
“This is happening all over the world today. Well, the savings are quite extraordinary. You’re getting 60 times performance per dollar, 100 times speed up, you only increase your power by 3x, 100 times speed up, you only increase your cost by 1.5x.”
32:49
「節省是非常驚人的,節省是用美元來衡量的,許多公司在雲中處理數據上花費了數億美元,如果這些數據被加速,節省數億美元並不意外。」
“The savings are incredible. The savings are measured in dollars. It is very clear that many, many companies spend hundreds of millions of dollars processing data in the cloud. If it was accelerated, it is not unexpected that you could save hundreds of millions of dollars.”
33:02
「這是為什麼呢?原因很明顯,我們在通用計算中經歷了這麼長時間的膨脹,現在我們終於決定加速,有大量的捕獲損失,我們現在可以重新獲得,大量的捕獲的浪費,我們現在可以減少,這將轉化為節省,節省金錢,節省能源。」
“Now, why is that? Well, the reason for that is very clear. We’ve been experiencing inflation for so long in general-purpose computing. Now that we finally came to, we finally determined to accelerate, there’s an enormous amount of captured loss that we can now regain, a great deal of captured retained waste that we can now relieve out of the system, and that will translate into savings. Savings in money, savings in energy.”
33:38
「這就是為什麼你聽到我說,買得越多,省得越多。」
“And that’s the reason why you’ve heard me say, the more you buy, the more you save.”
33:52
「現在我已經給你展示了數學原理,這不準確但它是正確的。」
“And now I’ve shown you the mathematics. It is not accurate, but it is correct.”
33:59
「這被稱為CEO數學,CEO數學是不準確的,但它是正確的,買得越多,省得越多。」
“Okay, that’s called CEO math. CEO math is not accurate, but it is correct. The more you buy, the more you save.”
34:10
「加速計算確實帶來了非凡的結果,但這並不容易,為什麼它節省了這麼多錢,但人們這麼久以來卻沒有這樣做?原因是因為它非常難。」
“Well, accelerated computing does deliver extraordinary results, but it is not easy. Why is it that it saves so much money, but people haven’t done it for so long? The reason for that is because it’s incredibly hard.”
34:20
「沒有一種軟件,你可以通過一個C編譯器運行它,突然間那個應用程序就能快100倍,這甚至是不合邏輯的,如果可能做到這一點,他們早就更換了CPU來做這件事。」
“There is no such thing as a software that you can just run through a C compiler and all of a sudden that application runs 100 times faster. That is not even logical. If it was possible to do that, they would have just changed the CPU to do that.”
34:40
「事實上,你必須重寫軟件,這就是困難的部分,軟件必須完全重寫,這樣你才能重新設計和表達在CPU上編寫的算法,使其可以加速,卸載,加速並並行運行。」
“You, in fact, have to rewrite the software. That’s the hard part. The software has to be completely rewritten so that you could re-architect, re-express the algorithms that were written on a CPU so that it could be accelerated, offloaded, accelerated, and run in parallel.”
35:03
「這個計算機科學的練習是非常困難的,但我們已經使世界變得容易了,在過去的20年中,當然非常著名的cuDNN,處理神經網絡的深度學習庫。」
“That computer science exercise is insanely hard. Well, we’ve made it easy for the world over the last 20 years. Of course, the very famous cuDNN, the deep learning library that processes neural networks.”
35:18
「我們有一個AI物理學庫,你可以用來流體動力學和許多其他應用,神經網絡必須遵守物理定律,我們有一個很棒的新庫叫做Aerial,是一個CUDA加速的5G無線電,這樣我們可以軟件定義並加速電信網絡,就像我們軟件定義了世界的網絡,互聯網一樣。」
“We have a library for AI physics that you could use for fluid dynamics and many other applications where the neural network has to obey the laws of physics. We have a great new library called Aerial that is a CUDA-accelerated 5G radio, so that we can software define and accelerate the telecommunications networks the way that we’ve software defined the world’s networking, the internet.”
35:44
「因此,我們加速這些的能力使我們能夠將所有的電信轉變為基本上和雲計算平台一樣的計算平台。」
“And so, the ability for us to accelerate that allows us to turn all of telecom into essentially the same type of platform, a computing platform just like we have in the cloud.”
36:01
「Kitho是一個計算光學平台,允許我們處理芯片製造中最計算密集的部分,製作掩模,台積電正在使用Kitho進行生產,節省了大量的能源和金錢,但台積電的目標是加速他們的技術堆棧,以便為未來做好準備。」
“Kitho is a computational lithography platform that allows us to process the most computationally intensive parts of chip manufacturing, making the mask. TSMC is in the process of going to production with Kitho, saving enormous amounts of energy and enormous amounts of money. But the goal for TSMC is to accelerate their stack so that they’re prepared for even further.”
36:22
「算法的進步和更多的計算將使得越來越深、越來越窄的晶體管進一步發展。Parabr是我們的基因測序庫,這是世界上吞吐量最高的基因測序庫。Coopt是一個令人難以置信的組合優化庫,用於路徑規劃優化和旅行推銷員問題,非常複雜,人們,科學家們大多認為需要量子計算機來解決。」
“Advances in algorithms and more computation for deeper and deeper narrow and narrow transistors. Parabr is our gene sequencing library. It is the highest throughput library in the world for gene sequencing. Coopt is an incredible library for combinatorial optimization, route planning optimization, the traveling salesman problem, incredibly complicated. People, well, scientists have largely concluded that you needed a quantum computer to do that.”
36:52
「我們創建了一個算法,運行在加速計算上,速度非常快,我們今天擁有23項世界紀錄。我們今天持有所有主要的世界紀錄。」
“We created an algorithm that runs on accelerated computing that runs lightning fast. We hold 23 world records. We hold every single major world record today.”
37:01
「C Quantum是一個量子計算機的模擬系統,如果你想設計一個量子計算機,你需要一個模擬器來做,如果你想設計量子算法,你需要一個量子模擬器來做。」
“C Quantum is an emulation system for a quantum computer. If you want to design a quantum computer, you need a simulator to do so. If you want to design quantum algorithms, you need a quantum emulator to do so.”
37:14
「你會怎麼做?如果量子計算機不存在,你怎麼設計這些量子計算機,創建這些量子算法?你使用今天世界上最快的計算機,我們稱之為Nvidia Cuda,在上面有一個模擬器模擬量子計算機,它被世界各地的數百名研究人員使用。」
“How would you do that? How would you design these quantum computers, create these quantum algorithms if the quantum computer doesn’t exist? Well, you use the fastest computer in the world that exists today, and we call it, of course, Nvidia Cuda. And on that, we have an emulator that simulates quantum computers. It is used by several hundred researchers around the world.”
37:39
「它集成到所有領先的量子計算框架中,並被世界各地的科學超級計算中心使用。」
“It is integrated into all the leading frameworks for quantum computing and is used in scientific supercomputing centers all over the world.”
37:48
「CDF是一個令人難以置信的數據處理庫,數據處理佔用了今天雲計算的大部分支出,所有這些都應該加速。CDF加速了世界上主要的庫,比如Spark,許多人可能在公司中使用過Spark。」
“CDF is an unbelievable library for data processing. Data processing consumes the vast majority of cloud spend today. All of it should be accelerated. CDF accelerates the major libraries used in the world, like Spark. Many of you probably use Spark in your companies.”
38:12
「Pandas,一個新的叫做Polar的庫,還有NetworkX,一個圖處理數據庫庫。這些只是一些例子,還有很多,每一個都需要創建,這樣我們才能讓生態系統利用加速計算。」
“Pandas, a new one called Polar, and of course, NetworkX, which is a graph processing, graph processing database library. And so these are just some examples. There are so many more. Each one of them had to be created so that we can enable the ecosystem to take advantage of accelerated computing.”
38:32
「如果我們沒有創建CNN,僅僅有Cuda是不可能讓全世界的深度學習科學家使用的,因為Cuda和在TensorFlow和PyTorch中使用的算法之間的差距太大了。這幾乎就像嘗試沒有OpenGL的計算機圖形一樣,就像沒有SQL的數據處理一樣。」
“If we hadn’t created CNN, Cuda alone wouldn’t have been possible for all of the deep learning scientists around the world to use because Cuda and the algorithms that are used in TensorFlow and PyTorch, the deep learning algorithms, the separation is too far apart. It’s almost like trying to do computer graphics without OpenGL. It’s almost like doing data processing without SQL.”
39:06
「這些特定領域的庫是我們公司的珍寶。我們有350個這樣的庫,這些庫使我們能夠進入這麼多市場。我今天會給你們展示一些其他的例子。」
“These domain-specific libraries are really the treasure of our company. We have 350 of them. These libraries are what it takes and what has made it possible for us to open so many markets. I’ll show you some other examples today.”
39:17
「就在上週,谷歌宣布他們在雲中加入了CDF,並加速了Pandas。Pandas是世界上最流行的數據科學庫,許多在座的可能已經使用過Pandas,全世界有1000萬數據科學家使用,每月下載量達1.7億次。」
“Well, just last week, Google announced that they put CDF in the cloud and accelerated Pandas. Pandas is the most popular data science library in the world. Many of you here probably already use Pandas. It’s used by 10 million data scientists in the world, downloaded 170 million times each month.”
39:40
「這是數據科學家的Excel表格。現在只需一鍵,你就可以在Google的雲數據中心平台上使用加速的Pandas,速度提升是非常驚人的。」
“It is the Excel, the spreadsheet of data scientists. Well, with just one click, you can now use Pandas in Colab, which is Google’s cloud data centers platform, accelerated by QDF. The speed up is really incredible.”
40:11
「那是一個很棒的演示,對吧?沒花很長時間。當你加速數據處理這麼快,演示不會花很長時間。」
“That was a great demo, right? Didn’t take long. When you accelerate data processing that fast, demos don’t take long.”
40:28
「好吧,現在Cuda已經達到了人們所說的臨界點,但它甚至比這更好。Cuda現在已經達到了一個良性循環,這是很少發生的事情。」
“Okay, well, Cuda has now achieved what people call a tipping point, but it’s even better than that. Cuda has now achieved a virtuous cycle. This rarely happens.”
40:40
「如果你看看歷史上的所有計算架構和計算平台,在微處理器CPU的情況下,它已經存在了60年,這60年來沒有改變過。」
“If you look at history and all the computing architecture and computing platforms, in the case of microprocessor CPUs, it has been here for 60 years. It has not been changed for 60 years.”
40:59
「這種計算方式沒有改變過。加速計算已經出現很久了,創建一個新平台是極其困難的,因為這是一個雞和蛋的問題。如果沒有開發人員使用你的平台,那麼當然就沒有用戶。但如果沒有用戶,就沒有安裝基礎。如果沒有安裝基礎,開發人員就不感興趣。開發人員想為一個大的安裝基礎寫軟件,但一個大的安裝基礎需要很多應用程序,這樣用戶才會創建這個安裝基礎。」
“This way of doing computing has not changed. Accelerated computing has been around for a long time. Creating a new platform is extremely hard because it’s a chicken and egg problem. If there are no developers that use your platform, then of course there will be no users. But if there are no users, there are no installed base. If there are no installed base, developers aren’t interested in it. Developers want to write software for a large installed base, but a large installed base requires a lot of applications so that users would create that installed base.”
41:36
「這個雞或蛋的問題很少被打破,現在已經花了我們20年,一個領域庫接一個領域庫,一個加速庫接一個加速庫,現在我們有全球500萬開發人員。」
“This chicken or the egg problem has rarely been broken, and it’s taken us now 20 years, one domain library after another, one acceleration library after another, and now we have 5 million developers around the world.”
41:46
「我們服務於每一個行業,從醫療保健、金融服務、當然還有計算機行業、汽車行業,幾乎所有主要行業,幾乎每個科學領域。」
“We serve every single industry, from healthcare, financial services, of course the computer industry, automotive industry, just about every major industry in the world, just about every field of science.”
42:06
「因為有這麼多我們架構的客戶,OEM和雲服務提供商有興趣構建我們的系統,系統製造商,像台灣這裡的優秀系統製造商有興趣構建我們的系統,然後將更多系統提供給市場。」
“Because there are so many customers for our architecture, OEMs and cloud service providers are interested in building our systems. System makers, amazing system makers like the ones here in Taiwan, are interested in building our systems, which then takes and offers more systems to the market.”
42:17
「這當然為我們創造了更大的機會,這讓我們能夠增加我們的規模,研發規模,進一步加速應用程序。每次我們加速應用程序,計算成本就會下降。」
“Which, of course, creates greater opportunity for us, which allows us to increase our scale, R&D scale, which speeds up the application even more. Well, every single time we speed up the application, the cost of computing goes down.”
42:28
「這就是我之前展示給你的幻燈片,100倍的速度提升轉化為97%、96%、98%的節省。所以當我們從100倍速度提升到200倍速度提升到1000倍速度提升,計算的邊際成本會繼續下降。」
“This is that slide I was showing you earlier. 100x speed up translates to 97%, 96%, 98% savings. So when we go from 100x speed up to 200x speed up to 1000x speed up, the savings, the marginal cost of computing continues to fall.”
42:59
「我們相信,通過大幅降低計算成本,市場、開發者、科學家和發明家將繼續發現新的算法,消耗越來越多的計算資源,直到有一天發生某種轉變,計算的邊際成本低到出現一種新的計算機使用方式。」
“Well, of course, we believe that by reducing the cost of computing incredibly, the market, developers, scientists, inventors will continue to discover new algorithms that consume more and more and more computing. So that one day something happens, that a phase shift happens, that the marginal cost of computing is so low that a new way of using computers emerges.”
43:28
「事實上,這就是我們現在看到的。多年來,我們降低了計算的邊際成本,在過去的十年裡,在一個特定算法上降低了一百萬倍。因此,現在訓練大語言模型變得非常合乎邏輯和常識,用互聯網上的所有數據來訓練。」
“In fact, that’s what we’re seeing now. Over the years, we have driven down the marginal cost of computing. In the last 10 years, in one particular algorithm, by a million times. Well, as a result, it is now very logical and very common sense to train large language models with all of the data on the internet.”
43:50
「沒有人會再想兩次。這個創建一台能夠處理如此多數據的計算機的想法,使其可以自己寫軟件,人工智能的出現是因為我們完全相信如果我們使計算越來越便宜,總有人會找到很好的用途。」
“Nobody thinks twice. This idea that you could create a computer that could process so much data to write its own software. The emergence of artificial intelligence was made possible because of this complete belief that if we made computing cheaper and cheaper and cheaper, somebody’s going to find a great use.”
44:17
「好吧,今天Cuda已經達到了良性循環,安裝基礎在增長,計算成本在下降,這引起了更多開發人員提出更多想法,這推動了更多需求,現在我們處於非常重要的開始階段。」
“Well, today Cuda has achieved the virtuous cycle. Install base is growing, computing cost is coming down, which causes more developers to come up with more ideas, which drives more demand. And now we’re in the beginning of something very, very important.”
44:32
「但在我展示給你看之前,我想展示的是,如果沒有我們創建的Cuda,如果沒有我們創建的現代AI大爆炸,這一切是不可能的。」
“But before I show you that, I want to show you what is not possible if not for the fact that we created Cuda, that we created the modern version of the generative AI, the modern big bang of AI.”
44:50
「我即將展示的是不可能的。這是地球二號,創建地球的數字雙胞胎的想法,我們將模擬地球,這樣我們可以預測我們星球的未來,以更好地避免災難,或更好地理解氣候變化的影響,以便我們可以更好地適應,改變我們的行為習慣。」
“What I’m about to show you would not be possible. This is Earth Two, the idea that we would create a digital twin of the Earth, that we would go and simulate the Earth so that we could predict the future of our planet to better avert disasters or better understand the impact of climate change, so that we can adapt better, so that we could change our habits.”
45:22
「現在,這個地球的數字雙胞胎可能是世界上最雄心勃勃的項目之一,我們每年都在大步前進,我每年都會向你展示成果。今年我們取得了一些重大突破,讓我們來看看。」
“Now, this digital twin of Earth is probably one of the most ambitious projects that the world’s ever undertaken. And we’re taking large steps every single year, and I’ll show you results every single year. But this year, we made some great breakthroughs. Let’s take a look.”
45:43
「星期一,風暴將再次向北轉向並接近台灣,關於其路徑有很大的不確定性,不同的路徑將對台灣產生不同程度的影響。」
“On Monday, the storm will veer north again and approach Taiwan. There are big uncertainties regarding its path. Different paths will have different levels of impact on Taiwan.”
48:36
「在不久的將來,我們將在地球上的每一平方公里內進行連續的天氣預測,你將總是知道氣候將會是什麼,你將總是知道,這將持續運行,因為我們訓練了AI,AI所需的能量非常少,這是一個令人難以置信的成就。」
“Someday in the near future, we will have continuous weather prediction at every square kilometer on the planet. You will always know what the climate’s going to be. You will always know. And this will run continuously because we trained the AI, and the AI requires so little energy. And so this is just an incredible achievement.”
48:56
「我希望你們喜歡它,而且非常重要的是……」
“I hope you enjoyed it, and very importantly…”
49:12
「事實是,那是一個Jensen AI,不是我。我寫了它,但AI Jensen AI必須說出來。」
“The truth is, that was a Jensen AI. That was not me. I wrote it, but an AI Jensen AI had to say it.”
49:34
「由於我們致力於不斷提高性能、降低成本,研究人員在2012年發現了AI,這是Nvidia與AI的首次接觸,這是非常重要的一天。」
“Because of our dedication to continuously improve the performance and drive the cost down, researchers discovered AI. Researchers discovered CUDA in 2012. That was Nvidia’s first contact with AI. This was a very important day.”
49:55
「我們有幸與科學家合作,使深度學習成為可能,AlexNet實現了巨大的計算機視覺突破,但最大的智慧是退一步,了解深度學習的背景,它的基礎是什麼,長期影響是什麼,潛力是什麼。」
“We had the good wisdom to work with the scientists to make deep learning possible, and AlexNet achieved a tremendous computer vision breakthrough. But the great wisdom was to take a step back and understand the background of deep learning, what its foundation is, its long-term impact, and its potential.”
50:21
「我們意識到,這項技術具有巨大的潛力,可以擴展一個幾十年前發現的算法,突然間,由於更多的數據、更大的網絡和非常重要的更多計算,深度學習實現了人類算法無法實現的目標。」
“We realized that this technology has great potential to scale an algorithm that was invented and discovered decades ago. Suddenly, because of more data, larger networks, and very importantly, a lot more compute, deep learning was able to achieve what no human algorithm was able to.”
50:47
「現在想像一下,如果我們進一步擴展架構,更大的網絡,更多的數據,更多的計算,會發生什麼?所以我們決心在2012年之後重新發明一切。」
“Now imagine if we were to scale up the architecture even more: larger networks, more data, and more compute. What could be possible? So we dedicated ourselves to reinvent everything after 2012.”
50:59
「我們改變了GPU的架構,添加了張量核心。我們發明了NVLink,那是10年前的事。」
“We changed the architecture of our GPU to add tensor cores. We invented NVLink. That was 10 years ago.”
51:10
「現在,有了CNN、TensorRT、NCCL,我們收購了Mellanox、TensorRT、Triton推理服務器,這些都融合在一台全新的計算機上,沒有人理解,沒有人要求它,沒有人理解它,事實上,我確信沒有人想要購買它。」
“Now, CNN, TensorRT, NCCL, we bought Mellanox, TensorRT, Triton inference server, and all of it came together on a brand new computer. Nobody understood it, nobody asked for it, nobody understood it. And in fact, I was certain nobody wanted to buy it.”
51:31
「所以我們在GTC上宣布了一個小公司,OpenAI,一家位於舊金山的小公司看到它,並要求我送一台給他們。我交付了世界上第一台AI超級計算機DGX-1給OpenAI,那是2016年。」
“And so we announced it at GTC. An OpenAI, a small company in San Francisco, saw it, and they asked me to deliver one to them. I delivered the world’s first AI supercomputer, DGX-1, to OpenAI. That was 2016.”
51:57
「之後,我們繼續擴展,從一台AI超級計算機,一台AI設備,我們將其擴展到大型超級計算機,更大的超級計算機。到2017年,世界發現了Transformers。」
“Well, after that, we continued to scale from one AI supercomputer, one AI appliance. We scaled it up to large supercomputers, even larger. By 2017, the world discovered Transformers.”
52:09
「這使我們能夠訓練大量的數據,識別和學習跨越長時間序列的模式。現在,我們可以訓練這些大型語言模型,理解並實現自然語言理解的突破。」
“So that we could train enormous amounts of data and recognize and learn patterns that are sequential over large spans of time. It is now possible for us to train these large language models to understand and achieve a breakthrough in natural language understanding.”
52:25
「我們在那之後繼續前進,我們建造了更大的模型,然後在2022年11月,OpenAI宣布了ChatGPT,使用數千、數萬個Nvidia GPU訓練的大型AI超級計算機。五天後有100萬用戶,兩個月後有1億用戶,成為歷史上增長最快的應用。」
“And we kept going after that. We built even larger ones. And then in November 2022, OpenAI announced ChatGPT, trained on thousands, tens of thousands of Nvidia GPUs in a very large AI supercomputer. One million users after five days, one million after five days, 100 million after two months, the fastest-growing application in history.”
52:52
「原因很簡單,它非常容易使用,使用起來非常神奇。能夠像人一樣與計算機互動,而不需要清晰地表達你想要什麼,它理解你的意思,它理解你的意圖。」
“And the reason for that is very simple. It is just so easy to use, and it was so magical to use to be able to interact with a computer like it’s human. Instead of being clear about what you want, it’s like the computer understands your meaning. It understands your intention.”
53:23
「哦,我想這裡,它,它,嗯,最接近的夜市。夜市對我來說非常重要。」
“Oh, I think here it, it, um, as the closest night market. The night market is very important to me.”
53:29
「當我小時候,我想我大約四歲半,我喜歡去夜市,因為我喜歡看人。我的父母經常帶我們去夜市。」
“So when I was young, I think I was about four and a half years old, I used to love going to the night market because I just love watching people. And so we went, my parents used to take us to the night market.”
53:57
「我愛夜市。我愛去夜市。有一天,我的臉,你們可能會看到我臉上有一個大疤痕,因為有人在洗刀,我當時是個小孩子。但我對夜市的記憶非常深刻,因為這件事,我喜歡去夜市,我仍然喜歡。」
“And I love, I love the night market. I love going. And one day, my face, you guys might see that I have a large scar on my face, my face was cut because somebody was washing their knife and I was a little kid. But my memories of the night market are so deep because of that. And I used to love, I still love going to the night market.”
54:19
「我只需要告訴你們,台南夜市真的很好,因為有一位女士,她已經在那裡工作了43年,她是賣水果的,位置在兩個攤位中間。」
“And I just need to tell you guys this, the Tainan night market is really good because there’s a lady, she’s been working there for 43 years, she’s the fruit lady, and it’s in the middle of the street, the middle between the two. Go find her, okay?”
54:41
「她真的很棒。我覺得這會很有趣,在這之後,你們所有人都去找她,她每年都做得越來越好,她的攤位也改進了。我喜歡看她成功。」
“So she’s really terrific. I think it would be funny after this, all of you go to see her. Every year, she’s doing better and better. Her cart has improved, and yeah, I just love watching her succeed.”
55:05
「無論如何,ChatGPT 出現了,這張幻燈片非常重要,讓我給你們展示一下。」
“Anyways, ChatGPT came along, and something is very important in this slide here. Let me show you something.”
55:17
「這張幻燈片,根本的區別在於這裡。」
“This slide, the fundamental difference is this.”
55:23
「直到ChatGPT向世界展示之前,AI全部都是關於感知,自然語言理解,計算機視覺,語音識別,都是關於感知和檢測。」
“Until ChatGPT revealed it to the world, AI was all about perception, natural language understanding, computer vision, speech recognition. It’s all about perception and detection.”
55:48
「這是世界上第一次看到了生成型AI,它逐字產生令牌,這些令牌是單詞,當然現在這些令牌也可以是圖片、圖表或表格、歌曲、單詞、語音、視頻,這些令牌可以是任何東西,任何你可以理解其意義的東西。」
“This was the first time the world saw a generative AI. It produced tokens one token at a time, and those tokens were words. Some of the tokens, of course, could now be images or charts or tables, songs, words, speech, videos. Those tokens could be anything, anything that you can learn the meaning of.”
56:18
「它們可以是化學物質的令牌,蛋白質的令牌,基因的令牌。你之前在Earth 2中看到了,我們在生成天氣的令牌。」
“It could be tokens of chemicals, tokens of proteins, genes. You saw earlier in Earth 2, we were generating tokens of the weather.”
56:31
「我們可以學習物理學,如果你能學習物理學,你可以教AI模型物理學,AI模型可以學習物理學的意義,並且可以生成物理學。」
“We can learn physics. If you can learn physics, you could teach an AI model physics. The AI model could learn the meaning of physics, and it can generate physics.”
56:40
「我們將尺度縮小到1公里,不是通過過濾,而是生成。」
“We were scaling down to 1 kilometer not by using filtering, it was generating.”
56:52
「所以我們可以使用這種方法來生成幾乎任何有價值的東西。我們可以為汽車生成方向盤控制,我們可以為機械臂生成關節。」
“And so we can use this method to generate tokens for almost anything, almost anything of value. We can generate steering wheel control for a car. We can generate articulation for a robotic arm.”
57:11
「我們現在可以生成我們所學到的一切。我們已經不再處於AI時代,而是生成型AI時代。」
“Everything that we can learn, we can now generate. We have now arrived not at the AI era, but a generative AI era.”
57:24
「但真正重要的是這一點。」
“But what’s really important is this.”
57:28
「這台起初是超級計算機的計算機,現在已經演變成數據中心,它產生一件事,它產生令牌。這是一個AI工廠,這個AI工廠正在生成,創造,生產一些非常有價值的東西,一種新的商品。」
“This computer that started out as a supercomputer has now evolved into a data center, and it produces one thing. It produces tokens. It’s an AI factory. This AI factory is generating, creating, producing something of great value, a new commodity.”
57:53
「在19世紀90年代末,尼古拉·特斯拉發明了一個交流發電機,我們發明了一個AI發電機,交流發電機產生電子,Nvidia的AI發電機產生令牌。」
“In the late 1890s, Nikola Tesla invented an AC generator. We invented an AI generator. The AC generator generated electrons. Nvidia’s AI generator generates tokens.”
58:12
「這兩樣東西在幾乎每個行業都有很大的市場機會,它是完全可替代的,這就是為什麼它是一場新的工業革命。」
“Both of these things have large market opportunities. It’s completely fungible in almost every industry, and that’s why it’s a new industrial revolution.”
58:27
「我們現在有一個新的工廠,為每個行業生產一種新的商品,這種商品的價值是非凡的。這種方法的可擴展性非常高,這種方法的重複性非常強。」
“We have now a new factory producing a new commodity for every industry that is of extraordinary value. And the methodology for doing this is quite scalable, and the methodology of doing this is quite repeatable.”
58:44
「注意到有多少不同的AI模型,生成型AI模型每天都在被發明,各個行業現在都在加入。」
“Notice how quickly so many different AI models, generative AI models are being invented literally daily. Every single industry is now piling on.”
58:50
「這是第一次,IT行業,這個價值3萬億美元的IT行業,將要創造一些可以直接服務於價值100萬億美元的行業的東西。」
“For the very first time, the IT industry, which is a $3 trillion IT industry, is about to create something that can directly serve a hundred trillion dollars of industry.”
59:09
「它不再僅僅是信息存儲或數據處理的工具,而是為每個行業生成智能的工廠。這將成為一個製造業,不是製造計算機的製造業,而是使用計算機進行製造的製造業。這種情況從未發生過。」
“No longer just an instrument for information storage or data processing, but a factory for generating intelligence for every industry. This is going to be a manufacturing industry, not a manufacturing industry of computers, but using the computers in manufacturing. This has never happened before.”
59:36
「從加速計算開始,導致AI,導致生成型AI,現在導致一場工業革命。」
“Quite an extraordinary thing. What led started with accelerated computing, led to AI, led to generative AI, and now an industrial revolution.”
59:48
「現在,這對我們行業的影響也非常顯著。」
“Now, the impact to our industry is also quite significant.”
59:56
「當然,我們可以為許多行業創造一種新商品,一種新產品,我們稱之為令牌。」
“Of course, we could create a new commodity, a new product we call tokens for many industries.”
1:00:01
「但我們的影響也非常深遠。正如我之前所說,60年來,每一層計算都已經發生了變化,從CPU通用計算到加速GPU計算,計算機現在需要處理指令,現在計算機處理大型語言模型(LLMs)、AI模型。」
“But the impact of ours is also quite profound. For the very first time, as I was saying earlier, in 60 years, every single layer of computing has been changed from CPUs, general-purpose computing, to accelerated GPU computing, where the computer needs instructions. Now, computers process LLMs, large language models, AI models.”
1:00:25
「而過去的計算模型是基於檢索的,幾乎每次你觸摸手機時,都會為你檢索一些預先錄製的文本或預先錄製的圖像或預先錄製的視頻,並根據推薦系統重新組合,以根據你的習慣向你呈現。」
“And whereas the computing model of the past is retrieval-based, almost every time you touch your phone, some pre-recorded text or pre-recorded image or pre-recorded video is retrieved for you and recomposed based on a recommender system to present it to you based on your habits.”
1:00:47
「但在未來,你的計算機將盡可能多地生成,只檢索必要的東西。」
“But in the future, your computer will generate as much as possible, retrieve only what’s necessary.”
1:00:58
「原因是生成的數據需要的能量比檢索信息少,生成的數據也更具上下文相關性,它將編碼知識,它將編碼對你的理解。」
“And the reason for that is because generated data requires less energy to fetch information. Generated data also is more contextually relevant. It will encode knowledge, it will encode your understanding of you.”
1:01:12
「而不是說 ‘幫我獲取那個信息’ 或 ‘幫我獲取那個文件’,你只需要說 ‘給我一個答案’。」
“And instead of saying, ‘Get that information for me,’ or ‘Get that file for me,’ you just say, ‘Ask me for an answer.'”
1:01:25
「而不是你的計算機成為我們使用的工具,計算機現在將生成技能,它執行任務。」
“a tool to instead of your computer being a tool that we use, the computer will now generate skills. It performs tasks.”
1:01:37
「而不是一個生產軟件的行業,這在90年代初期是一個革命性的想法。」
“and instead of an industry that is producing software, which was a revolutionary idea in the early 90s.”
1:01:45
「記得微軟創造包裝軟件的想法,革命化了PC行業。沒有包裝軟件,我們會用PC做什麼?」
“remember the idea that Microsoft created for packaging software revolutionized the PC industry. Without packaged software, what would we use the PC to do?”
1:01:57
「這驅動了這個行業,現在我們有了一個新的工廠,一台新的計算機,我們將在其上運行一種新型的軟件,我們稱之為Nims,Nvidia推理微服務。」
“It drove this industry, and now we have a new factory, a new computer, and what we will run on top of this is a new type of software, and we call it Nims, Nvidia Inference Microservices.”
1:02:12
「現在發生的是,這個Nim運行在這個工廠內,這個Nim是一個預訓練的模型,它是AI。當然,這個AI本身是相當複雜的,但運行AI的計算堆棧非常複雜。」
“Now what happens is, the Nim runs inside this factory, and this Nim is a pre-trained model. It’s an AI. Well, this AI is of course quite complex in itself, but the computing stack that runs AIs are insanely complex.”
1:02:36
「當你使用ChatGPT時,其堆棧下面有大量的軟件,提示下有大量的軟件,而且非常複雜,因為模型很大,有數十億到數萬億的參數。」
“When you go and use ChatGPT, underneath their stack is a whole bunch of software, underneath that prompt is a ton of software, and it’s incredibly complex because the models are large, billions to trillions of parameters.”
1:02:50
「它不僅僅運行在一台計算機上,它運行在多台計算機上,必須分配工作負載到多個GPU上,有張量並行、流水線並行、數據並行,各種並行方式。」
“It doesn’t run on just one computer, it runs on multiple computers. It has to distribute the workload across multiple GPUs, tensor parallelism, pipeline parallelism, data parallelism, all kinds of parallelism.”
1:03:12
「如果你在一個工廠,如果你運行一個工廠,你的吞吐量直接關係到你的收入,你的吞吐量直接關係到服務質量,你的吞吐量直接關係到可以使用你的服務的人數。」
“Because if you are in a factory, if you run a factory, your throughput directly correlates to your revenues, your throughput directly correlates to quality of service, and your throughput directly correlates to the number of people who can use your service.”
1:03:30
「我們現在處於一個數據中心吞吐量利用率至關重要的世界,這在過去很重要,但不是最重要的。過去很重要,但人們不測量它。」
“We are now in a world where data center throughput utilization is vitally important. It was important in the past, but not the most important. It was important in the past, but people don’t measure it.”
1:03:41
「今天,每個參數都被測量,啟動時間、正常運行時間、利用率、吞吐量、空閒時間,你能想到的都被測量,因為它是一個工廠。當某些東西是一個工廠時,其運營直接關係到公司的財務表現。」
“Today, every parameter is measured, start time, uptime, utilization, throughput, idle time, you name it, because it’s a factory. When something is a factory, its operations directly correlate to the financial performance of the company.”
1:03:59
「所以我們意識到,這對大多數公司來說非常複雜,所以我們做了什麼呢?我們創建了一個AI盒子,容器內有令人難以置信的AMS軟件。」
“So we realized that this is incredibly complex for most companies to do. So what we did was we created this AI in a box, and the container has an incredible AMS of software.”
1:04:11
「在這個容器內是CUDA、cuDNN、TensorRT、Triton推理服務,它是雲原生的,所以你可以在Kubernetes環境中自動擴展。」
“Inside this container is CUDA, cuDNN, TensorRT, Triton for inference services. It is cloud-native so that you could auto-scale in a Kubernetes environment.”
1:04:25
「它有管理服務和鉤子,讓你可以監控你的AI。它有通用的API標準API,所以你可以真正與這個盒子聊天。」
“It has management services and hooks so that you can monitor your AIs. It has common APIs, standard APIs, so that you can literally chat with this box.”
1:04:36
「你下載這個Nim,你可以與它交談,只要你有CUDA在你的計算機上,當然,CUDA現在無處不在。」
“You download this Nim and you can talk to it, as long as you have CUDA on your computer, which is now of course everywhere.”
1:04:43
「它在每個雲上,從每個計算機製造商那裡可用,存在於數億台PC中。當你下載這個,你就有了一個AI,你可以像ChatGPT一樣與它聊天。」
“It’s in every cloud, available from every computer maker, it is available in hundreds of millions of PCs. When you download this, you have an AI and you can chat with it like ChatGPT.”
1:05:01
「所有的軟件現在都集成在一起,400個依賴項全都集成到一個中。我們測試了這個Nim,每一個預訓練模型在我們所有的安裝基礎上。」
“All of the software is now integrated, 400 dependencies all integrated into one. We tested this Nim, each one of these pre-trained models against our entire install base that’s in the cloud.”
1:05:13
「所有不同版本的Pascal和Ampere和Hopper,各種不同的版本,有些我甚至都忘了。」
“All the different versions of Pascal and Ampere and Hopper, and all kinds of different versions. I even forget some.”
1:05:28
「Nims是一個令人難以置信的發明,這是我最喜歡的之一,當然,正如你所知道的,我們現在有能力創建大型語言模型和各種類型的預訓練模型。」
“Nims is an incredible invention, this is one of my favorites. And of course, as you know, we now have the ability to create large language models and pre-trained models of all kinds.”
1:05:38
「我們有所有這些不同的版本,無論是基於語言的,還是基於視覺的,還是基於成像的,或者我們有適用於醫療保健的版本,數字生物學的版本,我們有數字人類的版本,我稍後會談到。」
“And we have all of these various versions, whether it’s language-based, or vision-based, or imaging-based, or we have versions available for healthcare, digital biology, we have versions that are digital humans that I’ll talk to you about.”
1:05:59
「使用這些的方法是,今天我們在Hugging Face上發布了優化的Llama 3 Nim,它在那裡可供你試用,你甚至可以帶走它,免費提供給你。」
“And the way you use this, just come to ai.nvidia.com. And today we just posted up in Hugging Face the Llama 3 Nim, fully optimized, it’s available there for you to try and you can even take it with you, it’s available to you for free.”
1:06:18
「所以你可以在雲中運行它,運行在任何雲中,你可以下載這個容器,放到你自己的數據中心,你可以託管它,使其可供你的客戶使用。」
“And so you could run it in the cloud, run it in any cloud, you could download this container, put it into your own data center, and you could host it, make it available for your customers.”
1:09:23
「將信息返回給團隊領導者,團隊領導者會推理並將信息呈現回給你,就像人類一樣。這是我們不久的將來,應用程序將會這樣。」
“to the team leader. The team leader would reason about that and present the information back to you, just like humans. This is in our near future, this is the way applications are going to look.”
1:09:37
「當然,我們可以用文本提示和語音提示與這些大型AI服務互動,但是有很多應用程序,我們希望與類似人類的形式互動。」
“Now, of course, we could interact with these large AI services with text prompts and speech prompts. However, there are many applications where we would like to interact with what is otherwise a humanlike form.”
1:09:52
「我們稱它們為數字人類,Nvidia一直在研究數字人類技術一段時間了。讓我來給你們展示一下,在此之前,等等,讓我先做點別的。」
“We call them digital humans. Nvidia has been working on digital human technology for some time. Let me show it to you, and well, before I do that, hang on a second, before I do that.”
1:10:07
「數字人類有潛力成為與你互動的偉大互動代理,它們使互動更加吸引人,它們可以更有同理心。」
“Digital humans have the potential of being a great interactive agent with you. They make interactions much more engaging, they could be much more empathetic.”
1:10:16
「當然,我們必須跨越這個令人難以置信的逼真鴻溝,讓數字人類顯得更加自然。這當然是我們的願景,這是我們希望去的地方。」
“And of course, we have to cross this incredible Chasm, this uncanny Chasm of realism, so that digital humans would appear much more natural. This is, of course, our vision. This is a vision of where we love to go.”
1:10:37
「讓我來給你們展示一下我們的進展。很高興在台灣,在我去夜市之前,讓我們深入了解一下數字人類的激動人心的前沿。」
“But let me show you where we are. Great to be in Taiwan. Before I head out to the night market, let’s dive into some exciting frontiers of digital humans.”
1:10:46
(影片)「想像一個未來,計算機與我們互動就像人類一樣。你好,我叫Sophie,我是Unique的數字人類品牌大使。這是數字人類的不可思議的現實。」
“Imagine a future where computers interact with us just like humans can. Hi, my name is Sophie, and I am a digital human brand ambassador for Unique. This is the incredible reality of digital humans.”
1:11:02
「數字人類將革命化從客戶服務到廣告和遊戲的行業,數字人類的可能性是無限的。」
“Digital humans will revolutionize industries from customer service to advertising and gaming. The possibilities for digital humans are endless.”
1:11:13
「使用你用手機拍攝的當前廚房的掃描,它們將成為AI室內設計師,幫助生成美麗的逼真建議和採購材料和家具。」
“Using the scans you took of your current kitchen with your phone, they will be AI interior designers helping generate beautiful photorealistic suggestions and sourcing the materials and furniture.”
1:11:26
「我們已經生成了幾個設計選項供你選擇,它們還將成為AI客戶服務代理,使互動更加吸引人和個性化,或者數字醫護人員,將檢查患者,提供及時的個性化護理。」
“We have generated several design options for you to choose from. They’ll also be AI customer service agents, making the interaction more engaging and personalized, or digital healthcare workers who will check on patients, providing timely, personalized care.”
1:11:39
「我確實忘記告訴醫生我對青黴素過敏,這樣的話我還能服用這些藥物嗎?」
“Um, I did forget to mention to the doctor that I am allergic to penicillin. Is it still okay to take the medications?”
1:11:48
「你被開的抗生素Ciprofloxacin和Metronidazole不含青黴素,所以對你來說服用是完全安全的。」
“The antibiotics you’ve been prescribed, Ciprofloxacin and Metronidazole, don’t contain penicillin, so it’s perfectly safe for you to take them.”
1:11:58
「它們甚至會成為AI品牌大使,設定下一個市場營銷和廣告趨勢。」
“And they’ll even be AI brand ambassadors, setting the next marketing and advertising trends.”
1:12:03
「你好,我是IMA,日本的首位虛擬模特。生成式AI和計算機圖形學的新突破,使數字人類能夠以人類的方式與我們互動和理解。」
“Hi, I’m IMA, Japan’s first virtual model. New breakthroughs in generative AI and computer graphics let digital humans see, understand, and interact with us in humanlike ways.”
1:12:22
「從我看到的情況來看,你似乎在某種錄音或製作設置中。」
“From what I can see, it looks like you’re in some kind of recording or production setup.”
1:12:25
「數字人類的基礎是基於多語言語音識別和合成以及理解和生成對話的LLMs。」
“The foundation of digital humans are AI models built on multilingual speech recognition and synthesis and LLMs that understand and generate conversation.”
1:12:45
「AI與另一個生成式AI連接,動態動畫化一個逼真的3D面部網格,最終使模型能夠再現逼真的外觀,實現實時路徑追蹤的次表面散射,以模擬光線穿透皮膚並在各點散射和退出,賦予皮膚其柔軟和透明的外觀。」
“The AIs connect to another generative AI to dynamically animate a lifelike 3D mesh of a face. Finally, models reproduce lifelike appearances, enabling real-time path-traced subsurface scattering to simulate the way light penetrates the skin, scatters, and exits at various points, giving skin its soft and translucent appearance.”
1:13:09
「Nvidia Ace是一套數字人類技術,包裝成易於部署的完全優化的微服務或Nims。開發人員可以將Ace Nims集成到他們現有的框架、引擎和數字人類體驗中。」
“Nvidia Ace is a suite of digital human technologies packaged as easy to deploy, fully optimized microservices or Nims. Developers can integrate Ace Nims into their existing frameworks, engines, and digital human experiences.”
1:13:20
「Nvidia Ace是一套數字人類技術,包裝成易於部署的完全優化的微服務或Nims。開發人員可以將Ace Nims集成到他們現有的框架、引擎和數字人類體驗中,Neotron SLM和LLM Nims用於理解我們的意圖並協調其他模型,Reva語音Nims用於互動語音和翻譯,Audio to Face和Gesture Nims用於面部和身體動畫,Omniverse RTX和DLSS用於神經渲染皮膚和頭髮。」
“Nvidia Ace is a suite of digital human technologies packaged as easy-to-deploy, fully optimized microservices or Nims. Developers can integrate Ace Nims into their existing frameworks, engines, and digital human experiences. Neotron SLM and LLM Nims to understand our intent and orchestrate other models, Reva speech Nims for interactive speech and translation, Audio to Face and Gesture Nims for facial and body animation, and Omniverse RTX with DLSS for neuro-rendering of skin and hair.”
1:13:48
「Ace Nims運行在Nvidia GDN上,這是一個由Nvidia加速基礎設施組成的全球網絡,提供低延遲的數字人類處理,覆蓋超過100個地區。」
“Ace Nims run on Nvidia GDN, a global network of Nvidia accelerated infrastructure that delivers low-latency digital human processing to over 100 regions.”
1:14:13
「哈,這真的很不可思議。這些Ace運行在雲端,但它也可以在個人電腦上運行。我們明智地在所有RTX中包括了Tensor Core GPU,所以我們已經為這一天做了準備。」
“Haha, pretty incredible. Well, those Ace runs in the cloud, but it also runs on PCs. We had the good wisdom of including Tensor Core GPUs in all of RTX, so we’ve been shipping AI GPUs for some time, preparing ourselves for this day.”
1:14:34
「原因很簡單,我們一直知道,要創建一個新的計算平台,你需要先安裝基礎,最終應用程序會來臨。如果你不創建安裝基礎,應用程序怎麼可能來臨?」
“The reason for that is very simple. We always knew that in order to create a new computing platform, you need to install the base first. Eventually, the application will come. If you don’t create the install base, how could the application come?”
1:14:50
「所以,如果你建造了它們,他們可能不會來,但如果你不建造它們,他們絕對不會來。所以我們在每一個RTX GPU中安裝了Tensor Core處理器。」
“And so, if you build it, they might not come, but if you don’t build it, they cannot come. And so we installed every single RTX GPU with Tensor Core processing.”
1:15:01
「現在,我們在全球擁有1億個GeForce RTX AI PC,並且正在運輸200萬台。」
“And now we have 100 million GeForce RTX AI PCs in the world, and we’re shipping 200 million.”
1:15:08
「這次Computex,我們推出了四款新的驚人筆記本電腦,它們都能運行AI。」
“And this Computex, we’re featuring four new amazing laptops. All of them are able to run AI.”
1:15:13
「你未來的筆記本電腦,你未來的PC將會成為AI,它們會不斷地在背景中幫助你、協助你。」
“Your future laptop, your future PC will become an AI. They’ll be constantly helping you, assisting you in the background.”
1:15:20
「PC也將運行由AI增強的應用程序,當然,你所有的照片編輯、寫作和工具,所有你使用的東西都會由AI增強。」
“The PC will also run applications that are enhanced by AI. Of course, all your photo editing, your writing, and your tools, all the things that you use, will all be enhanced by AI.”
1:15:35
「你的PC還將托管具有數字人類的應用程序,這些應用程序是AI。因此,AI將以不同的方式呈現在PC中,PC將成為一個非常重要的AI平台。」
“And your PC will also host applications with digital humans that are AIs. And so, there are different ways that AIs will manifest themselves and become used in PCs, but PCs will become a very important AI platform.”
1:15:54
「那麼,我們從這裡去哪裡呢?我早些時候談到了我們數據中心的擴展,每次我們擴展時,我們都發現了一個新的階段變化。」
“So, where do we go from here? I spoke earlier about the scaling of our data centers, and every single time we scaled, we found a new phase change.”
1:16:04
「當我們從DGX擴展到大型AI超級計算機時,我們使Transformers能夠在巨大的數據集上進行訓練。」
“When we scaled from DGX into large AI supercomputers, we enabled Transformers to be able to train on enormously large data sets.”
1:16:17
「一開始,數據是人工監督的,需要人工標記來訓練AI。不幸的是,人工標記的數據是有限的。Transformers使無監督學習成為可能。」
“Well, what happened was, in the beginning, the data was human-supervised. It required human labeling to train AIs. Unfortunately, there is only so much you can human label. Transformers made it possible for unsupervised learning to happen.”
1:16:36
「現在,Transformers可以查看大量數據,查看大量視頻,或者查看大量圖像,它們可以通過學習大量數據來自己發現模式和關係。」
“Now, Transformers just look at an enormous amount of data or look at an enormous amount of video or look at an enormous amount of images, and it can learn from studying an enormous amount of data to find the patterns and relationships itself.”
1:16:55
「下一代AI需要以物理為基礎。今天的大多數AI不理解物理定律,它們沒有在物理世界中紮根。」
“Well, the next generation of AI needs to be physically based. Most of the AIs today don’t understand the laws of physics; they’re not grounded in the physical world.”
1:17:01
「為了生成圖像、視頻和3D圖形以及許多物理現象,我們需要以物理為基礎並理解物理定律的AI。」
“In order for us to generate images and videos and 3D graphics and many physics phenomena, we need AIs that are physically based and understand the laws of physics.”
1:17:14
「我們可以通過學習視頻來實現這一點,這是一種方法,另一種方法是使用合成數據、模擬數據,還有一種方法是使用計算機相互學習。」
“Well, the way that you could do that, that is, of course, learning from video, is one source. Another way is synthetic data, simulation data, and another way is using computers to learn with each other.”
1:17:22
「這實際上與使用AlphaGo讓AlphaGo自我對弈沒有什麼不同。兩個相同能力的AI長期對弈,會變得更聰明。」
“This is really no different than using AlphaGo, having AlphaGo play itself, self-play, and between the two capabilities, same capabilities playing each other for a very long period of time, they emerge even smarter.”
1:17:41
「因此,你將開始看到這種AI出現。」
“And so, you’re going to start to see this type of AI emerging.”
1:17:46
「如果AI數據是合成生成的,並使用強化學習,那麼數據生成的速度將繼續增長。每次數據生成增長,我們需要提供的計算量也需要隨之增長。」
“Well, if the AI data is synthetically generated and using reinforcement learning, it stands to reason that the rate of data generation will continue to advance. And every single time data generation grows, the amount of computation that we have to offer needs to grow with it.”
1:18:01
「我們即將進入一個AI可以學習物理定律並理解並紮根於物理世界數據的階段。」
“We are about to enter a phase where AI can learn the laws of physics and understand and be grounded in physical world data.”
1:18:06
「因此,我們預計模型將繼續增長,我們需要更大的GPU。」
“And so we expect that models will continue to grow, and we need larger GPUs.”
1:18:11
「我們即將進入一個階段,AI可以學習物理定律,理解並扎根於物理世界的數據。因此,我們預計模型將繼續增長,我們需要更大的GPU。」
“We are about to enter a phase where AI can learn the laws of physics and understand and be grounded in physical world data. And so we expect that models will continue to grow, and we need larger GPUs.”
1:18:24
「Blackwell正是為這一代設計的。這就是Blackwell,它具備幾個非常重要的技術。首先,當然是芯片的尺寸。我們採用了兩個最大的芯片,這是TSMC能製造的最大的芯片,我們把它們連接在一起,用10TB/s的鏈接連接世界上最先進的CIE。」
“Well, Blackwell was designed for this generation. This is Blackwell, and it has several very important technologies. One, of course, is just the size of the chip. We took two of the largest chips that TSMC can make, and we connected them together with a 10 terabytes per second link between the world’s most advanced CIEs.”
1:18:52
「我們然後將它們安裝在一個計算節點上,並連接了一個灰色CPU。灰色CPU可以在訓練情況下用於快速檢查點和重啟,在推理和生成的情況下,它可以用於存儲上下文記憶,使AI有記憶並理解對話的上下文。」
“We then put two of them on a computer node connected with a gray CPU. The gray CPU could be used for several things. In the training situation, it could be used for fast checkpoint and restart. In the case of inference and generation, it could be used for storing context memory so that the AI has memory and understands the context of the conversation.”
1:19:19
「這是我們的第二代Transformer引擎,Transformer引擎允許我們根據所需的精度和範圍動態調整到更低的精度。」
“It’s our second-generation Transformer engine. The Transformer engine allows us to adapt dynamically to a lower precision based on the precision and the range necessary for that layer of computation.”
1:19:34
「這是我們的第二代GPU,具有安全AI功能,可以請求服務提供商保護你的AI免受盜竊或篡改。」
“This is our second-generation GPU that has secure AI, so you could ask your service providers to protect your AI from being either stolen or tampered with.”
1:19:39
「這是我們的第五代NVLink,NVLink允許我們將多個GPU連接在一起,我會稍後展示更多。」
“This is our fifth-generation NVLink. NVLink allows us to connect multiple GPUs together, and I’ll show you more of that in a second.”
1:19:55
「這也是我們的第一代具有可靠性和可用性引擎的GPU系統,這個系統允許我們測試每一個晶體管、觸發器、內存,包括片上內存和片外內存,以便在現場確定某個芯片是否失效。」
“This is also our first generation with a reliability and availability engine. This system allows us to test every single transistor, flip-flop, memory, on-chip memory, and off-chip memory, so that we can determine in the field whether a particular chip is failing.”
1:20:14
「10,000個GPU的超級計算機的平均故障時間(MTBF)以小時計算,而100,000個GPU的超級計算機的平均故障時間以分鐘計算。因此,要讓超級計算機長時間運行並訓練一個可能持續數月的模型,實際上是不可能的,除非我們發明了增強其可靠性的技術。可靠性當然會提高其運行時間,這直接影響成本。」
“The meantime between failure (MTBF) of a supercomputer with 10,000 GPUs is measured in hours, and the meantime between failure of a supercomputer with 100,000 GPUs is measured in minutes. So, the ability for a supercomputer to run for a long period of time and train a model that could last for several months is practically impossible if we don’t invent technologies to enhance its reliability. Reliability would, of course, enhance its uptime, which directly affects the cost.”
1:20:56
「最後是解壓引擎,數據處理是我們必須做的最重要的事情之一。我們增加了一個數據壓縮引擎和解壓引擎,使我們可以比今天可能的速度快20倍從存儲中提取數據。」
“And then lastly, the decompression engine. Data processing is one of the most important things we have to do. We added a data compression engine and decompression engine so that we can pull data out of storage 20 times faster than what’s possible today.”
1:21:10
「這些都是Blackwell的特點,我們在GTC上展示了Blackwell的原型。」
“Well, all of this represents Blackwell, and I think we have one here that’s in production. During GTC, I showed you Blackwell in a prototype state.”
1:21:15
「女士們先生們,這是Blackwell。」
“Ladies and gentlemen, this is Blackwell.”
1:21:49
「Blackwell正在生產中,擁有難以置信的技術量。這是我們的生產板,這是世界上最複雜、性能最高的計算機。」
“Blackwell is in production, with incredible amounts of technology. This is our production board; this is the most complex, highest-performance computer the world has ever made.”
1:22:08
「這是灰色CPU,你可以看到這裡的每一個Blackwell芯片,兩個連接在一起。這是世界上最大的芯片,然後我們用10TB/s的鏈接將兩個芯片連接在一起,這就是Blackwell計算機。」
“This is the gray CPU, and you can see each one of these Blackwell chips, two of them connected together. This is the largest chip the world makes, and then we connect two of them together with a 10 terabytes per second link. That makes the Blackwell computer.”
1:22:28
「性能是驚人的,看看這個。」
“And the performance is incredible. Take a look at this.”
1:22:42
「你看,我們每一代的計算能力,AI FLOPS,在8年內增加了1000倍。摩爾定律在8年內大約是40到60倍,而在過去8年中,摩爾定律下降了很多。」
“You see, our computational FLOPS, the AI FLOPS for each generation, has increased by a thousand times in eight years. Moore’s Law in eight years is something along the lines of, oh, I don’t know, maybe 40 to 60 times. And in the last eight years, Moore’s Law has gone a lot less.”
1:23:13
「所以,僅僅比較摩爾定律在最好的時候與Blackwell的表現,就可以看到計算量是多麼驚人。而每當我們提高計算量,成本就會下降。我們通過提高計算能力,減少了訓練一個2萬億參數、8萬億Tokens的GPT模型所需的能量350倍。」
“So, just to compare, even Moore’s Law at its best of times, compared to what Blackwell could do, the amount of computations is incredible. And whenever we bring the computation high, the thing that happens is the cost goes down. We’ve increased through its computational capability, reducing the energy used to train a GPT-4, a 2 trillion parameter, 8 trillion tokens model, by 350 times.”
1:23:56
「Pascal 需要 1,000 吉瓦時的電力,1,000 吉瓦時意味著它需要一個吉瓦級的數據中心,世界上沒有一個吉瓦級的數據中心。但如果你有一個吉瓦級的數據中心,它需要一個月。如果你有一個 100 兆瓦級的數據中心,它大約需要一年。」
“Pascal would have taken 1,000 gigawatt hours. 1,000 gigawatt hours means that it would take a gigawatt data center. The world doesn’t have a gigawatt data center, but if you had a gigawatt data center, it would take a month. If you had a 100 megawatt data center, it would take about a year.”
1:24:20
「因此,沒有人會當然會創建這樣的東西。這就是為什麼這些大型語言模型如 Chat GPT 在八年前是不可能的。通過提高性能,並在提高能源效率的過程中保持和改進能源效率,我們現在將 Blackwell 所需的 1,000 吉瓦時降到 3 吉瓦時。」
“And so nobody, of course, would create such a thing. And that’s the reason why these large language models like Chat GPT weren’t possible only eight years ago. By increasing the performance and improving energy efficiency along the way, we’ve now taken what used to be 1,000 gigawatt hours with Blackwell down to 3 gigawatt hours.”
1:24:46
「如果是 10,000 個 GPU,比如說,它只需要幾天,大約 10 天。所以在短短八年內取得的進展是令人難以置信的。」
“If it’s a 10,000 GPU setup, for example, it would only take a few days, about 10 days or so. So the amount of advance in just eight years is incredible.”
1:25:00
「這是為推理設計的,這是為生成 token 設計的。我們的 token 生成性能使我們能夠將能源消耗降低 3 到 4 倍,最多 45,000 倍。」
“Well, this is for inference. This is for token generation. Our token generation performance has made it possible for us to drive the energy down by three to four, up to 45,000 times.”
1:25:18
「177,000 焦耳每個 token,那是 Pascal 的情況。177,000 焦耳相當於兩個燈泡運行兩天的能量。它需要兩個燈泡運行兩天的 200 瓦特能量來生成一個 token。」
“177,000 joules per token. That was Pascal. 177,000 joules is kind of like two light bulbs running for two days. It would take two light bulbs running for two days’ worth of energy, 200 watts running for two days, to generate one token.”
1:25:42
「生成一個 GPT-4 token 大約需要三個 token,所以 Pascal 生成 GPT-4 token 並提供 Chat GPT 體驗所需的能量幾乎是不可能的。但現在我們只需要 0.4 焦耳每個 token,我們可以以驚人的速度生成 token,消耗非常少的能量。」
“It takes about three tokens to generate one word in GPT-4, so the amount of energy necessary for Pascal to generate GPT-4 tokens and have a Chat GPT experience with you was practically impossible. But now we only use 0.4 joules per token, and we can generate tokens at incredible rates and very little energy.”
1:26:05
「所以 Blackwell 是一個巨大的飛躍。但即便如此,它還是不夠大,所以我們需要建造更大的機器。」
“Okay, so Blackwell is just an enormous leap. Well, even so, it’s not big enough, and so we have to build even larger machines.”
1:26:16
「我們這樣構建的方法叫做 DGX,這是我們的 Blackwell 芯片,安裝在 DGX 系統中。」
“And so the way that we build it is called DGX. So this is our Blackwell chips, and it goes into DGX systems.”
1:26:38
「這就是 DGX Blackwell,它是空冷的,內部有八個 GPU。看看這些 GPU 散熱器的大小,大約是 15 千瓦,完全是空冷的。這個版本支持 x86 架構,它可以進入我們一直在發送 Hopper 的基礎設施中。」
“So this is a DGX Blackwell. This is air-cooled, has eight of these GPUs inside. Look at the size of the heat sinks on these GPUs, about 15 kilowatts, and completely air-cooled. This version supports x86, and it goes into the infrastructure that we’ve been shipping Hoppers into.”
1:27:13
「然而,如果你想要液冷,我們有一個新的系統,這個新系統基於這個板子,我們稱之為 MGX,它是模塊化的。」
“However, if you would like to have liquid cooling, we have a new system, and this new system is based on this board, and we call it MGX for modular.”
1:27:25
「這是 MGX 系統,這是兩個 Blackwell 板子,每個節點有四個 Blackwell 芯片,這些四個 Blackwell 芯片是液冷的。」
“This is the MGX system, and here are the two Blackwell boards. So this one node has four Blackwell chips. These four Blackwell chips are liquid-cooled.”
1:28:06
「九個這樣的節點,共 72 個 GPU,我們使用第五代 NVLink 連接它們,這是 NVLink 開關,這是一個技術奇蹟,數據速率驚人,這些開關將所有的 Blackwell 連接在一起,使我們擁有一個巨大的 72 GPU Blackwell。」
“Nine of them, well, 72 of these GPUs, 72 of these GPUs are then connected together with a new NVLink. This is NVLink switch, fifth generation, and the NVLink switch is a technology miracle. The data rate is insane, and these switches connect every single one of these Blackwells together so that we have one giant 72 GPU Blackwell.”
1:28:39
「好處是,在一個域中,這看起來像一個 GPU,這一個 GPU 有 72 個,而上一代只有 8 個。所以我們增加了九倍的帶寬,AI FLOPS 增加了 45 倍,而功耗只增加了 10 倍。這是 100 千瓦,而上一代是 10 千瓦。」
“The benefit of this is that in one domain, this now looks like one GPU. This one GPU has 72 versus the last generation’s eight. So we increased it by nine times, the bandwidth by 18 times, the AI FLOPS by 45 times, and yet the power is only 10 times. This is 100 kilowatts, and the last generation was 10 kilowatts.”
1:29:10
「當然,你可以連接更多的這些,我稍後會展示如何做到這一點。但奇蹟在於這個芯片,這是 NVLink 芯片,人們開始意識到 NVLink 芯片的重要性,因為它連接所有這些不同的 GPU。因為大型語言模型太大,不適合一個 GPU,也不適合一個節點,需要一整個 GPU 機架。」
“Well, of course, you can always connect more of these together, and I’ll show you how to do that in a second. But what’s the miracle is this chip, this NVLink chip. People are starting to awaken to the importance of this NVLink chip as it connects all these different GPUs together. Because the large language models are so large, they don’t fit on just one GPU or just one node. It’s going to take an entire rack of GPUs.”
1:29:37
「這個新的 DGX,我剛才站在它旁邊,用來容納數萬億參數的大型語言模型,NVLink 開關本身就是一個技術奇蹟,有 500 億個晶體管,74 個端口,每個端口 400 Gbps,總帶寬 7.2 TB/s。」
“This new DGX that I was just standing next to, to hold a large language model that has tens of trillions of parameters. The NVLink switch in itself is a technology miracle, with 50 billion transistors, 74 ports at 400 Gbps each, a cross-sectional bandwidth of 7.2 TB/s.”
1:29:59
「其中一個重要的功能是它在開關內部有數學計算功能,可以在芯片上進行歸約,這對深度學習非常重要。」
“But one of the important things is that it has mathematics inside the switch so that we can do reductions right on the chip, which is really important in deep learning.”
1:30:04
「這在深度學習中非常重要,就在芯片上進行。因此,這就是 DGX 現在的樣子,很多人問我們,他們說,對 Nvidia 做什麼有很多困惑,以及 Nvidia 是如何在構建 GPU 方面變得如此巨大的。」
“That’s important in deep learning, right on the chip. And so this is what a DGX looks like now. And a lot of people ask us, they say, there’s this confusion about what Nvidia does and how it became so big building GPUs.”
1:30:31
「所以有一種印象認為這就是 GPU 的樣子。現在這是一個 GPU,這是世界上最先進的 GPU 之一,但這是一個遊戲 GPU。但你和我知道這才是 GPU 的樣子,這是一個 DGX GPU。」
“And so there’s an impression that this is what a GPU looks like. Now, this is a GPU. This is one of the most advanced GPUs in the world, but this is a gamer GPU. But you and I know that this is what a GPU looks like, this is a DGX GPU.”
1:30:57
「在這個 GPU 的背面是 MVLink 主幹,MVLink 主幹有 5,000 根電纜,長達兩英里,它就在這裡。」
“The back of this GPU is the MVLink spine. The MVLink spine is 5,000 wires, two miles, and it’s right here.”
1:31:20
「這是一個 MVLink 主幹,它將 702 個 GPU 連接在一起,這是一個電氣機械奇蹟。收發器使我們能夠用銅纜驅動整個長度,結果這個 NVLink 開關使用銅纜驅動 NVLink 主幹,使我們能夠在一個機架上節省 20 千瓦的功率。」
“This is an MVLink spine, and it connects 702 GPUs to each other. This is an electrical mechanical miracle. The transceivers make it possible for us to drive the entire length in copper, and as a result, this NVLink switch driving the NVLink spine in copper makes it possible for us to save 20 kilowatts in one rack.”
1:32:12
「即使這樣,對於 AI 工廠來說也不夠大,因此我們必須用非常高速的網絡將其全部連接在一起。我們有兩種類型的網絡:Infiniband 和以太網。」
“Even this is not big enough for AI factories, so we have to connect it all together with very high-speed networking. We have two types of networking: Infiniband and Ethernet.”
1:32:34
「Infiniband 已經在超級計算和 AI 工廠中使用,並且增長非常快。然而,並不是每個數據中心都能處理 Infiniband,因為他們已經在以太網上投入了太多的生態系統,並且需要一些專業知識來管理 Infiniband 開關和網絡。因此,我們將 Infiniband 的能力帶到了以太網架構中,這非常困難。」
“Infiniband has been used in supercomputing and AI factories all over the world and is growing incredibly fast for us. However, not every data center can handle Infiniband because they’ve already invested their ecosystem in Ethernet for too long, and it takes some specialty and expertise to manage Infiniband switches and networks. So we’ve brought the capabilities of Infiniband to the Ethernet architecture, which is incredibly hard.”
1:33:02
「以太網是為高平均吞吐量設計的,因為每個節點,每台計算機都連接到互聯網上的不同人,大部分通信是數據中心與互聯網另一端的人進行通信。然而,深度學習和 AI 工廠中的 GPU 並不是主要與互聯網上的人進行通信,而是主要彼此通信。」
“Ethernet was designed for high average throughput because every single node, every single computer is connected to a different person on the internet, and most of the communications is the data center with somebody on the other side of the internet. However, in deep learning and AI factories, the GPUs are not mostly communicating with people on the internet, they are communicating with each other.”
1:33:34
「它們相互通信,因為它們正在收集部分產品,然後必須將其減少並重新分配。這些部分產品的減少和重新分配流量非常突發,重要的不是平均吞吐量,而是最後的到達。」
“They are communicating with each other because they are collecting partial products and then have to reduce and redistribute them. This traffic is incredibly bursty, and it’s not the average throughput that matters, it’s the last arrival.”
1:33:55
「以太網沒有為此提供條款,因此我們必須創建一些東西。我們創建了一個端到端的架構,使網卡和開關可以通信,我們應用了四種不同的技術來實現這一點。」
“Ethernet has no provision for that, and so there are several things that we had to create. We created an end-to-end architecture so that the NIC and the switch can communicate, and we applied four different technologies to make this possible.”
1:34:33
「首先,Nvidia 擁有世界上最先進的 RDMA,現在我們有能力為以太網提供網絡級別的 RDMA。第二,我們有擁堵控制,開關始終進行遙測,並且非常快,無論何時 GPU 或網卡發送過多信息,我們可以告訴它們減少以防止熱點。」
“Number one, Nvidia has the world’s most advanced RDMA, and now we have the ability to have a network-level RDMA for Ethernet. Number two, we have congestion control, the switch does telemetry at all times, incredibly fast, and whenever the GPUs or the NICs are sending too much information, we can tell them to back off to prevent hotspots.”
1:35:04
「第三,自適應路由,以太網需要按順序發送和接收,我們看到擁堵或未使用的端口,我們將其發送到可用的端口,而 Bluefield 在另一端重新排序,使其按順序返回。自適應路由非常強大。」
“Number three, adaptive routing. Ethernet needs to transmit and receive in order. We see congestion or unused ports, we will send it to the available ports, and Bluefield on the other end reorders it so that it comes back in order. That adaptive routing is incredibly powerful.”
1:35:30
「最後,噪聲隔離。在數據中心中同時有多個模型正在訓練或其他事情發生,它們的噪聲和流量會相互干擾並導致抖動。」
“And lastly, noise isolation. There are more than one model being trained or something happening in the data center at all times, and their noise and their traffic could get into each other and cause jitter.”
1:35:44
「當一個訓練模型的噪音導致最後到達時間太晚時,這確實會減慢訓練的速度。總之,請記住,您建立了一個 50 億美元或 30 億美元的數據中心,並使用它來進行訓練。如果網絡利用率降低了 40%,那麼訓練時間將增加 20%。」
“When the noise of one training model causes the last arrival to be too late, it really slows down the training. Overall, remember, you have built a $5 billion or $3 billion data center and you’re using it for training. If the network utilization was 40% lower, the training time would be 20% longer.”
1:36:17
「這樣的 50 億美元數據中心實際上就像一個 60 億美元的數據中心,所以成本影響非常高。以太網使用 Spectrum X 基本上使我們能夠大幅提升性能,讓網絡基本上是免費的,這確實是一個成就。我們有一整條以太網產品線,這是 Spectrum X800,速率為 51.2 Tbps 和 256 Radix。接下來的一款是 512 Radix,一年後會推出,名為 Spectrum X800 Ultra,而之後的一款是 X1600。」
“The $5 billion data center effectively becomes like a $6 billion data center, so the cost impact is quite high. Ethernet with Spectrum X basically allows us to improve performance so much that the network is basically free, and so this is really an achievement. We have a whole pipeline of Ethernet products, this is Spectrum X800, it is 51.2 terabits per second and 256 Radix. The next one coming is 512 Radix, one year from now, called Spectrum X800 Ultra, and the one after that is X1600.”
1:37:08
「X800 是為數萬個 GPU 設計的,X800 Ultra 是為數十萬個 GPU 設計的,X1600 是為數百萬個 GPU 設計的。數百萬個 GPU 數據中心的時代即將來臨,原因非常簡單。我們當然希望訓練更大規模的模型,但更重要的是,未來幾乎您與互聯網或計算機的每一次互動都可能有一個生成式 AI 在某處運行。」
“X800 is designed for tens of thousands of GPUs, X800 Ultra is designed for hundreds of thousands of GPUs, and X1600 is designed for millions of GPUs. The days of millions of GPU data centers are coming, and the reason for that is very simple. Of course, we want to train much larger models, but very importantly, in the future almost every interaction you have with the internet or with a computer will likely have a generative AI running somewhere.”
1:37:42
「那個生成式 AI 在與您一起工作、互動,生成視頻、圖像或文本,甚至可能是數字人。因此,您幾乎一直在與計算機互動,並且總是有一個生成式 AI 連接到那裡。部分是在內部,部分在您的設備上,很多可能在雲端。這些生成式 AI 也將進行大量的推理能力,而不是僅僅一次性回答,它們可能會迭代答案,以便在提供給您之前提高答案的質量。」
“That generative AI is working with you, interacting with you, generating videos, images, or text, maybe even a digital human. So, you’re interacting with your computer almost all the time, and there’s always a generative AI connected to that. Some of it is on-premises, some of it is on your device, and a lot of it could be in the cloud. These generative AIs will also do a lot of reasoning capabilities, instead of just one-shot answers, they might iterate on answers to improve the quality before giving them to you.”
1:38:15
「未來我們將進行的生成數量將是驚人的。現在讓我們來看看這些合在一起的結果。今晚是我們的第一次夜間主題演講,我想感謝所有今晚 7 點來到這裡的人們。我即將展示的內容有一種新的氛圍,這是一種夜間主題演講的氛圍,請享受這個時刻。」
“The amount of generation we’re going to do in the future is going to be extraordinary. Let’s take a look at all of this put together now. Tonight is our first nighttime keynote. I want to thank all of you for coming out tonight at 7:00 PM. What I’m about to show you has a new vibe, okay, there’s a nighttime keynote vibe, so enjoy this.”
1:39:02
「Blackwell 當然是 Nvidia 平台的第一代產品,在世界知道生成式 AI 時代來臨之際推出。正如世界意識到 AI 工廠的重要性,這正是一場新的工業革命的開始。我們得到了大量支持,幾乎每家 OEM,每家計算機製造商,每家 CSP,每家 GPU 雲服務商,甚至電信公司和全球的企業,對 Blackwell 的採用和熱情令人難以置信,我想感謝所有人。」
“Blackwell, of course, is the first generation of Nvidia platforms that was launched as the world knows the generative AI era is here. Just as the world realized the importance of AI factories, this is the beginning of a new industrial revolution. We have received so much support, nearly every OEM, every computer maker, every CSP, every GPU cloud provider, even telecommunication companies and enterprises all over the world. The amount of adoption and enthusiasm for Blackwell is just really off the charts, and I want to thank everyone.”
1:42:04
「我們並沒有停止。在這段驚人的增長期間,我們希望確保繼續提高性能,繼續降低訓練成本和推理成本,並繼續擴展 AI 能力,讓每家公司都能夠接受。我們提高性能越多,成本下降越多。Hopper 平台當然是有史以來最成功的數據中心處理器之一,這真是一個令人難以置信的成功故事。然而,Blackwell 已經來了,每個平台都是完整的平台,我們建造整個平台,並將其整合到 AI 工廠超級計算機中。」
“We’re not stopping there. During this time of incredible growth, we want to make sure that we continue to enhance performance, drive down the cost of training and inference, and scale out AI capabilities for every company to embrace. The further we drive up performance, the greater the cost decline. The Hopper platform, of course, was one of the most successful data center processors in history, and this is just an incredible success story. However, Blackwell is here, and every single platform is a complete platform. We build the entire platform and integrate it into an AI factory supercomputer.”
1:43:02
「然後我們將其解構並提供給世界,這樣您就可以創建有趣和創新的配置,各種不同風格,適應不同的數據中心和客戶,不同的地方,有些適合邊緣,有些適合電信,所有不同的創新都可以實現。我們設計並整合它,但我們解構後提供給您,這樣您就可以創建模塊化系統。Blackwell 平台已經來了,我們的公司按照一年一個節奏運行。」
“We then disaggregate it and offer it to the world so that you can create interesting and innovative configurations, different styles, fitting different data centers, customers, and places. Some of it for edge, some for telco, all kinds of different innovations are possible. We design and integrate it, but we offer it disaggregated so that you can create modular systems. The Blackwell platform is here, our company operates on a one-year rhythm.”
1:43:55
「我們的基本理念非常簡單:一,建造整個數據中心規模的解構平台並以零件形式出售,每年推動技術極限。我們推動一切到技術極限,無論是 TSMC 的工藝技術、包裝技術、記憶體技術、光學技術,一切都推向極限。然後,我們以這種方式進行,以便我們所有的軟件都能在整個安裝基礎上運行。軟件慣性是計算機中最重要的事情之一。」
“Our basic philosophy is very simple: one, build entire data center scale disaggregated and sell it in parts, push everything to the technology limits every year. We push everything to the technology limits, whether it’s TSMC process technology, packaging technology, memory technology, optics technology, everything is pushed to the limit. Then we do everything in such a way that all of our software runs on this entire install base. Software inertia is the single most important thing in computers.”
1:44:41
「當計算機向後兼容且與所有已創建的軟件在架構上兼容時,你的市場推廣能力會變得非常迅速。所以當我們能夠利用已創建的整個軟件基礎時,速度是令人難以置信的。Blackwell 已經來了,明年是 Blackwell Ultra,就像我們有 h100 和 h200 一樣,你可能會看到一些非常令人興奮的新一代產品。」
“When a computer is backwards compatible and architecturally compatible with all the software that has already been created, your ability to go to market is incredibly fast. So when we can take advantage of the entire install base of software that’s already been created, the velocity is incredible. Blackwell is here, next year is Blackwell Ultra. Just as we had h100 and h200, you’ll probably see some pretty exciting new generation from us for Blackwell Ultra.”
1:45:00
「我們再次推動極限,並推出下一代 Spectrum 交換機。我提到過,這是第一次進行的下一步,我還不確定是否會後悔。我們公司有代號,並且我們試圖保密。通常大多數員工甚至都不知道。但我們的下一代平台叫做 Reuben 平台。」
“We again push to the limits, and the next generation Spectrum switches I mentioned, well, this is the very first time that this next step has been made, and I’m not sure yet whether I’m going to regret this or not. We have code names in our company, and we try to keep them very secret. Often times most of the employees don’t even know. But our next generation platform is called Reuben, the Reuben platform.”
1:45:50
「Reuben 平台,我不會花太多時間講它。我知道會發生什麼事,你們會拍照,然後去看細節,隨意吧。所以我們有 Reuben 平台,一年後我們會有 Reuben Ultra 平台。我展示的所有這些芯片都在全面開發中,節奏是一年,推動技術極限,所有 100% 都在架構上兼容。」
“The Reuben platform, I’m not going to spend much time on it. I know what’s going to happen, you’re going to take pictures of it, and you’re going to go look at the fine prints, feel free to do that. So we have the Reuben platform, and one year later we have the Reuben Ultra platform. All of these chips that I’m showing you here are all in full development, the rhythm is one year at the limits of technology, all 100% architecturally compatible.”
1:46:11
「這基本上就是 Nvidia 正在建設的內容,並且所有豐富的軟件都在其上運行。在很多方面,從我們意識到計算未來將徹底改變的那一刻,到今天的過去 12 年,正如我之前展示的那樣,GeForce 在 2010 年之前和今天的 Nvidia,公司確實發生了巨大的變化。我想感謝所有合作夥伴一路上的支持。」
“This is basically what Nvidia is building, and all the riches of software on top of it. In a lot of ways, from the moment we realized that the future of computing was going to radically change to today, over the last 12 years, as I was holding up earlier, GeForce pre-2010 and Nvidia today, the company has really transformed tremendously. I want to thank all of our partners here for supporting us every step along the way.”
1:47:00
「這是 Nvidia Blackwall 平台。讓我談談接下來的事情。下一波 AI 是物理 AI,理解物理定律的 AI 能夠在我們中間工作。他們必須理解世界模型,這樣才能理解如何解釋世界,如何感知世界。他們當然必須具備出色的認知能力,這樣他們才能理解我們的要求並完成任務。」
“This is the Nvidia Blackwall platform. Let me talk about what’s next. The next wave of AI is physical AI, AI that understands the laws of physics and can work among us. They have to understand the world model so that they understand how to interpret the world, how to perceive the world. They, of course, have to have excellent cognitive capabilities so they can understand us, understand what we ask, and perform the tasks.”
1:47:34
「未來,機器人將是一個更普遍的概念。當我說機器人時,通常會想到類人機器人,但那並不完全正確。所有的工廠都將是機器化的,工廠將協調機器人,而這些機器人將製造機器化的產品。機器人與機器人互動,製造機器化的產品。」
“In the future, robotics will be a much more pervasive idea. Of course, when I say robotics, there’s usually the representation of humanoid robots, but that’s not at all true. All the factories will be robotic. The factories will orchestrate robots, and those robots will be building robotic products. Robots interacting with robots building robotic products.”
1:48:08
「為了做到這一點,我們需要取得一些突破。讓我給你們展示一下視頻。機器人時代已經到來。有一天,所有移動的東西都將是自主的。世界各地的研究人員和公司正在開發由物理 AI 驅動的機器人。物理 AI 是能夠理解指令並在現實世界中自主執行複雜任務的模型。」
“In order to do that, we need to make some breakthroughs. Let me show you the video. The era of robotics has arrived. One day, everything that moves will be autonomous. Researchers and companies around the world are developing robots powered by physical AI. Physical AIs are models that can understand instructions and autonomously perform complex tasks in the real world.”
1:48:44
「多模態大型語言模型 (LLM) 是使機器人能夠學習、感知和理解周圍世界並計劃其行動的突破。通過人類演示,機器人現在可以學習與世界互動所需的技能,使用粗略和精細的運動技能。推動機器人技術進步的其中一個核心技術是強化學習。就像 LLM 需要來自人類反饋的強化學習來學習特定技能一樣,生成的物理 AI 可以在模擬世界中使用來自物理反饋的強化學習來學習技能。」
“Multimodal large language models (LLMs) are breakthroughs that enable robots to learn, perceive, and understand the world around them and plan how they’ll act. From human demonstrations, robots can now learn the skills required to interact with the world using gross and fine motor skills. One of the integral technologies for advancing robotics is reinforcement learning. Just as LLMs need reinforcement learning from human feedback to learn particular skills, generative physical AI can learn skills using reinforcement learning from physics feedback in a simulated world.”
1:49:22
「這些模擬環境是機器人在遵循物理定律的虛擬世界中通過執行動作來做出決策的地方。在這些機器人健身房中,機器人可以安全快速地學習執行複雜和動態任務的技能,通過數百萬次試錯行為來改進其技能。我們構建了 Nvidia Omniverse 作為創建物理 AI 的操作系統。」
“These simulation environments are where robots learn to make decisions by performing actions in a virtual world that obeys the laws of physics. In these robot gyms, a robot can learn to perform complex and dynamic tasks safely and quickly, refining their skills through millions of acts of trial and error. We built Nvidia Omniverse as the operating system where physical AIs can be created.
1:49:55
「Omniverse 是一個虛擬世界模擬的開發平台,結合實時物理渲染、物理模擬和生成式 AI 技術。在 Omniverse 中,機器人可以學習如何成為機器人。他們學習如何自動化地精確操作物體,如抓握和處理物體,或自動導航環境,找到最佳路徑,同時避免障礙物和危險。」
“Omniverse is a development platform for virtual world simulation, combining real-time physically based rendering, physics simulation, and generative AI technologies. In Omniverse, robots can learn how to be robots. They learn how to autonomously manipulate objects with precision, such as grasping and handling objects, or navigate environments autonomously, finding optimal paths while avoiding obstacles and hazards.”
1:50:28
「在 Omniverse 中學習可以最大限度地減少模擬與現實之間的差距,並最大限度地傳遞所學行為。構建具有生成式物理 AI 的機器人需要三台計算機:Nvidia AI 超級計算機來訓練模型,Nvidia Jetson Orin 和下一代 Jetson Thor 機器人超級計算機來運行模型,以及 Nvidia Omniverse,機器人可以在其中學習和完善其技能。」
“Learning in Omniverse minimizes the sim-to-real gap and maximizes the transfer of learned behavior. Building robots with generative physical AI requires three computers: Nvidia AI supercomputers to train the models, Nvidia Jetson Orin and next-generation Jetson Thor robotic supercomputer to run the models, and Nvidia Omniverse where robots can learn and refine their skills.”
1:51:01
「我們構建了開發平台、加速庫和開發人員及公司需要的 AI 模型,並允許他們使用任何或所有最適合他們的堆疊。下一波 AI 已經來臨,由物理 AI 驅動的機器人將徹底改變行業。」
“We build the platforms, acceleration libraries, and AI models needed by developers and companies, and allow them to use any or all of the stacks that suit them best. The next wave of AI is here, robotics powered by physical AI will revolutionize industries.”
1:51:34
「這不是未來,這正在發生。我們將以幾種方式服務市場。首先,我們將為每種類型的機器人系統創建平台:一個用於機器人工廠和倉庫,一個用於操縱物體的機器人,一個用於移動的機器人,還有一個用於類人機器人的平台。」
“This isn’t the future, this is happening now. There are several ways that we’re going to serve the market. First, we’re going to create platforms for each type of robotic system: one for robotic factories and warehouses, one for robots that manipulate things, one for robots that move, and one for humanoid robots.”
1:52:01
「每一個機器人平台都像我們做的其他事情一樣:計算機、加速庫和預訓練模型。我們測試一切,訓練一切,並將一切整合到 Omniverse 中,正如視頻所說的,Omniverse 是機器人學習如何成為機器人的地方。」
“Each one of these robotic platforms is like almost everything else we do: a computer, acceleration libraries, and pre-trained models. We test everything, train everything, and integrate everything inside Omniverse, where, as the video was saying, robots learn how to be robots.”
1:52:22
「當然,機器人倉庫的生態系統非常複雜,需要很多公司、很多工具和很多技術來建造現代倉庫。倉庫越來越多地機器人化,有一天將完全是機器人化的。在每個生態系統中,我們都有連接到軟件行業的 SDK 和 API,連接到邊緣 AI 行業和公司,以及設計用於 PLC 和機器人系統的系統。」
“Of course, the ecosystem of robotic warehouses is really complex. It takes a lot of companies, a lot of tools, and a lot of technology to build a modern warehouse. Warehouses are increasingly robotic, and one day will be fully robotic. In each of these ecosystems, we have SDKs and APIs connected to the software industry, connected to edge AI industry and companies, and systems designed for PLCs and robotic systems.”
1:53:04
「然後由集成商整合,最終為客戶建造倉庫。這裡有一個例子,Kenmac 為 Giant Group 建造了一個機器人倉庫。」
“It’s then integrated by integrators, ultimately building warehouses for customers. Here we have an example of Kenmac building a robotic warehouse for Giant Group.”
1:53:22
「現在讓我們談談工廠。工廠有一個完全不同的生態系統,富士康正在建造一些世界上最先進的工廠。他們的生態系統包括邊緣計算機和設計工廠、工作流程和編程機器人的機器人軟件,當然還有協調數字工廠和 AI 工廠的 PLC 計算機。我們也有連接到每個生態系統的 SDK。」
“Now let’s talk about factories. Factories have a completely different ecosystem, and Foxconn is building some of the world’s most advanced factories. Their ecosystem includes edge computers and robotics software for designing the factories, workflows, and programming the robots, and of course PLC computers that orchestrate the digital factories and AI factories. We have SDKs connected to each of these ecosystems as well.”
1:53:54
「這正在台灣各地發生。富士康正在建造其工廠的數字孿生工廠,台達電子正在建造其工廠的數字孿生工廠。順便說一下,一半是實體,一半是數字,一半是 Omniverse。」
“This is happening all over Taiwan. Foxconn is building digital twins of their factories, Delta is building digital twins of their factories. By the way, half is real, half is digital, half is Omniverse.”
1:54:14
「和碩正在建造其機器人工廠的數字孿生工廠,緯創正在建造其機器人工廠的數字孿生工廠。這真的很酷,這是一段富士康新工廠的視頻。」
“Pegatron is building digital twins of their robotic factories, Wistron is building digital twins of their robotic factories. This is really cool, this is a video of Foxconn’s new factory.”
1:54:32
「隨著世界將傳統數據中心現代化為生成式 AI 工廠,對 Nvidia 加速計算的需求正在飆升。世界上最大的電子製造商富士康正在通過建設機器人工廠來滿足這一需求。」
“Demand for Nvidia accelerated computing is skyrocketing as the world modernizes traditional data centers into generative AI factories. Foxconn, the world’s largest electronics manufacturer, is gearing up to meet this demand by building robotic factories.”
1:54:53
「AI 工廠規劃者使用 Omniverse 將來自領先行業應用程序(如 Siemens Team Center X 和 Autodesk Revit)的設施和設備數據集成到數字孿生體中,優化工廠佈局和生產線配置,並定位最佳攝像機位置,以監控未來的操作。」
“AI factory planners use Omniverse to integrate facility and equipment data from leading industry applications like Siemens Team Center X and Autodesk Revit in the digital twin, optimizing floor layout and line configurations, and locating optimal camera placements to monitor future operations.”
1:55:15
「Nvidia Metropolis 提供的虛擬集成使規劃者在建設過程中節省了大量的物理變更訂單成本。富士康團隊使用數字孿生體作為真實信息的來源來溝通和驗證準確的設備佈局。」
“Virtual integration powered by Nvidia Metropolis saves planners an enormous cost of physical change orders during construction. The Foxconn teams use the digital twin as the source of truth to communicate and validate accurate equipment layout.”
1:55:36
「Omniverse 數字孿生體也是富士康開發人員訓練和測試 Nvidia Isaac AI 應用程序以進行機器人感知和操作的地方,還有 Metropolis AI 應用程序以進行傳感器融合。在 Omniverse 中,富士康在將運行時部署到 Jetson 計算機上的裝配線之前模擬兩個機器人 AI。」
“The Omniverse digital twin is also the robot gym
1:55:36
「Omniverse 數字孿生體也是富士康開發人員訓練和測試 Nvidia Isaac AI 應用程序以進行機器人感知和操作的地方,還有 Metropolis AI 應用程序以進行傳感器融合。在 Omniverse 中,富士康在將運行時部署到 Jetson 計算機上的裝配線之前模擬兩個機器人 AI。」
“The Omniverse digital twin is also the robot gym where Foxconn developers train and test Nvidia Isaac AI applications for robotic perception and manipulation and Metropolis AI applications for sensor fusion. In Omniverse, Foxconn simulates two robot AIs before deploying runtimes to Jetson computers on the assembly line.”
1:56:02
「他們模擬 Isaac 操控庫和 AI 模型,用於自動化光學檢測、物體識別、缺陷檢測和軌跡規劃,將 HGX 系統轉移到測試平台。他們模擬由 Isaac Perceptor 驅動的機器人 AMR,這些 AMR 能夠感知和移動其環境,進行 3D 映射和重建。」
“They simulate Isaac manipulator libraries and AI models for automated optical inspection, object identification, defect detection, and trajectory planning to transfer HGX systems to the test pods. They simulate Isaac Perceptor-powered robot AMRs as they perceive and move about their environment with 3D mapping and reconstruction.”
1:56:29
「通過 Omniverse,富士康建造了他們的機器人工廠,協調運行在 Nvidia Isaac 上的機器人來建造 Nvidia AI 超級計算機,而這些超級計算機反過來又訓練富士康的機器人。」
“With Omniverse, Foxconn builds their robotic factories that orchestrate robots running on Nvidia Isaac to build Nvidia AI supercomputers, which in turn train Foxconn robots.”
1:56:49
[掌聲] “so a robotic Factory is designed with…”
1:56:58
「三台計算機。Nvidia AI 訓練 AI,PLC 系統運行機器人協調工廠,然後當然所有東西都在 Omniverse 中模擬。機器人臂和機器人 AMR 也一樣,是三台計算機系統。不同的是,兩個 Omniverse 會合併,共享一個虛擬空間。當它們共享一個虛擬空間時,機器人臂將成為機器人工廠的一部分。」
“Three computers. Nvidia AI trains the AI, PLC systems run the robots orchestrating the factories, and then of course everything is simulated inside Omniverse. The robotic arm and the robotic AMRs are also the same way, three computer systems. The difference is the two Omniverse will come together so they’ll share one virtual space. When they share one virtual space, that robotic arm will become inside the robotic factory.”
1:57:36
「我們提供計算機、加速層和預訓練的 AI 模型。我們已經將 Nvidia Manipulator 和 Nvidia Omniverse 與 Siemens 這家全球領先的工業自動化軟件和系統公司聯繫起來。這真是一個了不起的合作夥伴關係,他們正在全球各地的工廠工作。」
“And again, three computers. We provide the computer, the acceleration layers, and pre-trained AI models. We’ve connected Nvidia Manipulator and Nvidia Omniverse with Siemens, the world’s leading industrial automation software and systems company. This is really a fantastic partnership, and they’re working on factories all over the world.”
1:58:01
「現在,Siemens Pi AI 已經集成了 Isaac Manipulator,並且 Siemens Pi AI 運行於 ABB、Fanuc、Yaskawa、Kuka、Universal Robotics 和 Techman 的設備上。Siemens 是一個了不起的集成,我們還有各種其他集成。」
“Siemens Pi AI now integrates Isaac Manipulator, and Siemens Pi AI runs and operates on ABB, Fanuc, Yaskawa, Kuka, Universal Robotics, and Techman equipment. Siemens is a fantastic integration, and we have all kinds of other integrations.”
1:58:20
「我們來看看。OurAR Best 正在將 Isaac Perceptor 集成到 Vox 智能自主機器人中,以增強物體識別和人類運動追踪及材料處理。BYD Electronics 正在將 Isaac Manipulator 和 Perceptor 集成到其 AI 機器人中,以提高全球客戶的製造效率。IdealWorks 正在將 Isaac Perceptor 集成到其 IW 軟件中,用於工廠物流中的 AI 機器人。」
“Let’s take a look. Our AR Best is integrating Isaac Perceptor into Vox smart autonomy robots for enhanced object recognition, human motion tracking, and material handling. BYD Electronics is integrating Isaac Manipulator and Perceptor into their AI robots to enhance manufacturing efficiencies for global customers. IdealWorks is building Isaac Perceptor into their IW software for AI robots in factory logistics.”
1:58:55
「ICS Intrinsic(Alphabet 公司的子公司)正在將 Isaac Manipulator 集成到其 FlowState 平台中,以推進機器人抓握技術。Gideon 正在將 Isaac Perceptor 集成到 Trey AI 驅動的叉車中,以推進 AI 物流。Argo Robotics 正在將 Isaac Perceptor 集成到 Perception Engine 中,以增強基於視覺的 AMR。Solomon 正在將 Isaac Manipulator AI 模型應用於其 AccuPick 3D 軟件中,用於工業操作。」
“ICS Intrinsic, an Alphabet company, is adopting Isaac Manipulator into their FlowState platform to advance robot grasping. Gideon is integrating Isaac Perceptor into Trey AI-powered forklifts to advance AI-enabled logistics. Argo Robotics is adopting Isaac Perceptor into Perception Engine for advanced vision-based AMRs. Solomon is using Isaac Manipulator AI models in their AccuPick 3D software for industrial manipulation.”
1:59:27
「Techman Robot 正在將 Isaac Sim 和 Manipulator 集成到其 TM Flow 中,以加速自動光學檢查。Teradyne Robotics 正在將 Isaac Manipulator 集成到 Polyscope X 中,用於協作機器人,並將 Isaac Perceptor 集成到 MiR AMR 中。VeNin 正在將 Isaac Manipulator 集成到 Machine Logic 中,用於 AI 操作機器人。」
“Techman Robot is adopting Isaac Sim and Manipulator into TM Flow to accelerate automated optical inspection. Teradyne Robotics is integrating Isaac Manipulator into Polyscope X for cobots and Isaac Perceptor into MiR AMRs. VeNin is integrating Isaac Manipulator into Machine Logic for AI manipulation robots.”
1:59:54
「機器人技術已經到來,物理 AI 已經到來,這不是科幻小說,它正在台灣各地被使用,這真的非常令人興奮。這是工廠,裡面的機器人,當然所有產品也將是機器人。現在有兩個高產量的機器人產品,一個當然是自駕車或具有高度自主能力的車輛。」
“Robotics is here, physical AI is here, this is not science fiction, and it’s being used all over Taiwan, and it’s really, really exciting. That’s the factory, the robots inside, and of course, all the products are going to be robotics. There are two very high-volume robotics products now, one of course is the self-driving car or cars that have a great deal of autonomous capability.”
2:00:18
「Nvidia 再次構建了整個堆棧。明年我們將與梅賽德斯車隊一起投入生產,之後在 2026 年與捷豹路虎車隊一起投入生產。我們向世界提供了完整的堆棧,然而,您可以選擇我們堆棧中的任何部分或任何層次。整個自駕堆棧都是開放的。」
“Nvidia again builds the entire stack. Next year, we’re going to go to production with the Mercedes fleet, and after that in 2026, the JLR fleet. We offered the full stack to the world; however, you’re welcome to take whichever parts, whichever layer of our stack. The entire self-driving stack is open.”
2:00:43
「下一個高產量的機器人產品將由機器人工廠生產,其中內部有機器人,可能是類人機器人。」
“The next high-volume robotics product that’s going to be manufactured by robotic factories with robots inside will likely be humanoid robots.
2:00:48
「類人機器人在近年來取得了巨大進展,無論是在基於基礎模型的認知能力,還是在我們正在開發的世界理解能力方面。我對這個領域非常興奮,因為顯然最容易適應世界的機器人是類人機器人,因為我們為自己建造了這個世界。」
“Humanoid robots have made great progress in recent years in both cognitive capability because of foundation models and also the world understanding capability that we’re in the process of developing. I’m really excited about this area because obviously the easiest robot to adapt into the world are humanoid robots because we built the world for us.”
2:01:12
「我們也擁有最多的數據來訓練這些機器人,比其他類型的機器人更多,因為我們擁有相同的體格。因此,我們可以通過演示能力和視頻能力提供大量的訓練數據,這將非常出色。所以我們會在這個領域看到很多進展。」
“We also have the vast amount of data to train these robots than other types of robots because we have the same physique. So the amount of training data we can provide through demonstration capabilities and video capabilities is going to be really great. So we’re going to see a lot of progress in this area.”
2:01:27
「嗯,我認為我們有一些機器人我們喜歡歡迎。他們差不多和我一樣高,還有一些朋友來加入我們。機器人技術的未來就在這裡,下一波 AI 來了。」
“Well, I think we have some robots that we like to welcome. There we go, about my size, and we have some friends to join us. So the future of robotics is here, the next wave of AI.”
2:01:54
「當然,你們知道,台灣製造鍵盤電腦,製造口袋裡的電腦,製造雲端數據中心的電腦,未來你們將製造可以行走的電腦和可以滾動的電腦。這些都是電腦。」
“And of course, you know, Taiwan builds computers with keyboards, you build computers for your pocket, you build computers for data centers in the cloud. In the future, you’re going to build computers that walk and computers that roll. These are all just computers.”
2:02:22
「事實證明,這些技術與你們今天建造的其他計算機的技術非常相似。所以這將是一個非常非凡的旅程。」
“And as it turns out, the technology is very similar to the technology of building all of the other computers that you already build today. So this is going to be a really extraordinary journey for us.”
2:02:34
「嗯,我想感謝大家。我製作了一個最後的視頻,如果你們不介意的話,這是我們真的很享受製作的。讓我們播放。」
“Well, I want to thank you all. I made one last video if you don’t mind, something that we really enjoyed making. Let’s run it.”
2:05:05
「謝謝你們,我愛你們。」
“Thank you, I love you guys.”
2:05:17
「謝謝大家的到來,祝你們有個美好的 Computex。」
“Thank you all for coming. Have a great Computex.”
2:05:26
「我在這裡,我呼喚你,我會讓你像我一樣。她和我一起唱歌,真的寶貝。」
“I am here, I call you, I will make you like me. She is singing with me, really baby.”
2:06:05
「一旦你來到 Computex,我們將向你展示一切。數字孿生和我在台灣的所有事情,希望你喜歡這首歌。」
“Once you come to Computex, we will show you all about everything. Digital twins and everything with me in Taiwan. We hope you like this song.”